
TensorFlow分区索引的使用
2018-10-10 17:22 更新
tf.dynamic_partition
dynamic_partition(
data,
partitions,
num_partitions,
name=None
)参见指南:张量变换>分割和连接
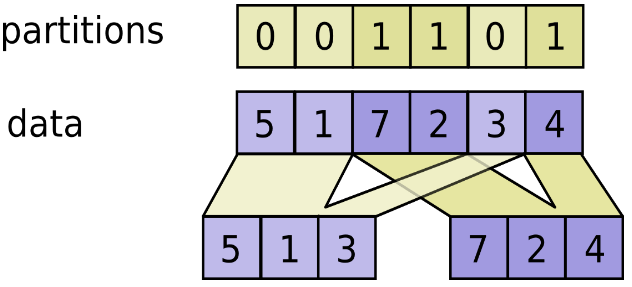
使用分区中的索引将数据分成 num_partitions 的张量.
对于大小为 partitions.ndim 的每个索引元组 js,切片数据为 [js, ...] ,成为 outputs[partitions[js]] 其中的一部分.这些 partitions[js] = i 切片以 js 的词典顺序被放置在 outputs[i] 中,outputs[i] 的第一个维度是分区中的条目数等于 i.详细参考如下:
outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:]
outputs[i] = pack([data[js, ...] for js if partitions[js] == i])data.shape 必须和 partitions.shape 一起启动.
例如:
# Scalar partitions.
partitions = 1
num_partitions = 2
data = [10, 20]
outputs[0] = [] # Empty with shape [0, 2]
outputs[1] = [[10, 20]]
# Vector partitions.
partitions = [0, 0, 1, 1, 0]
num_partitions = 2
data = [10, 20, 30, 40, 50]
outputs[0] = [10, 20, 50]
outputs[1] = [30, 40]有关 dynamic_stitch 如何将分区合并回来的示例.
ARGS:
- data:一个 Tensor.
- partitions:一个 int32 类型的张量.可以是任何形状.索引在范围 [0, num_partitions) 内.
- num_partitions:一个大于等于1的整数;要输出的分区数.
- name:操作的名称(可选).
返回:
与数据具有相同类型的 num_partitions 张量对象的列表.