
AIGC Flan 模型
扩展指令微调语言模型
有什么新内容?
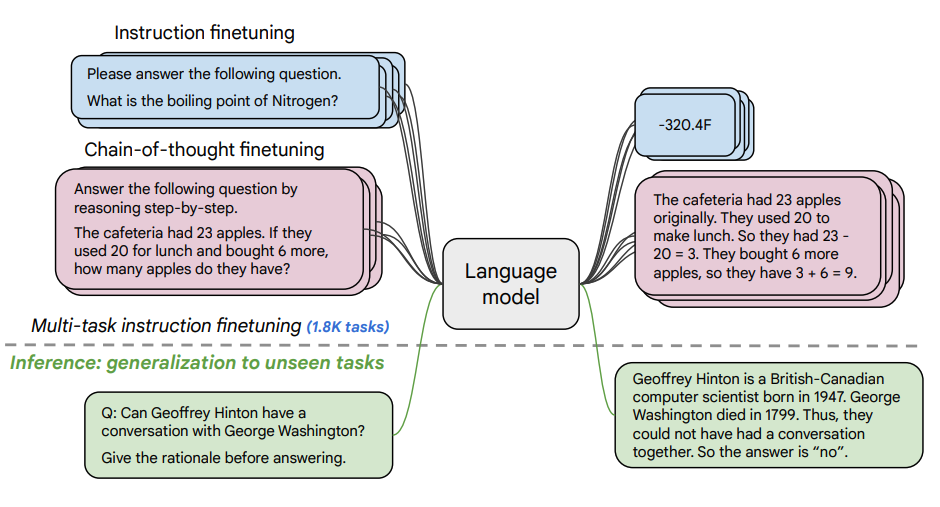
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
本文探讨了扩展指令微调(opens in a new tab)的好处,以及它如何提高各种模型(PaLM、T5)、提示设置(零样本、少样本、CoT)和基准(MMLU、TyDiQA)的性能。这是通过以下方面来探讨的:扩展任务数量(1.8K个任务)、扩展模型大小以及在思维链数据上微调(使用了9个数据集)。
微调过程:
- 1.8K个任务被表述为指令,并用于微调模型
- 使用有范例和无范例、有CoT和无CoT的方式
微调任务和保留任务如下:
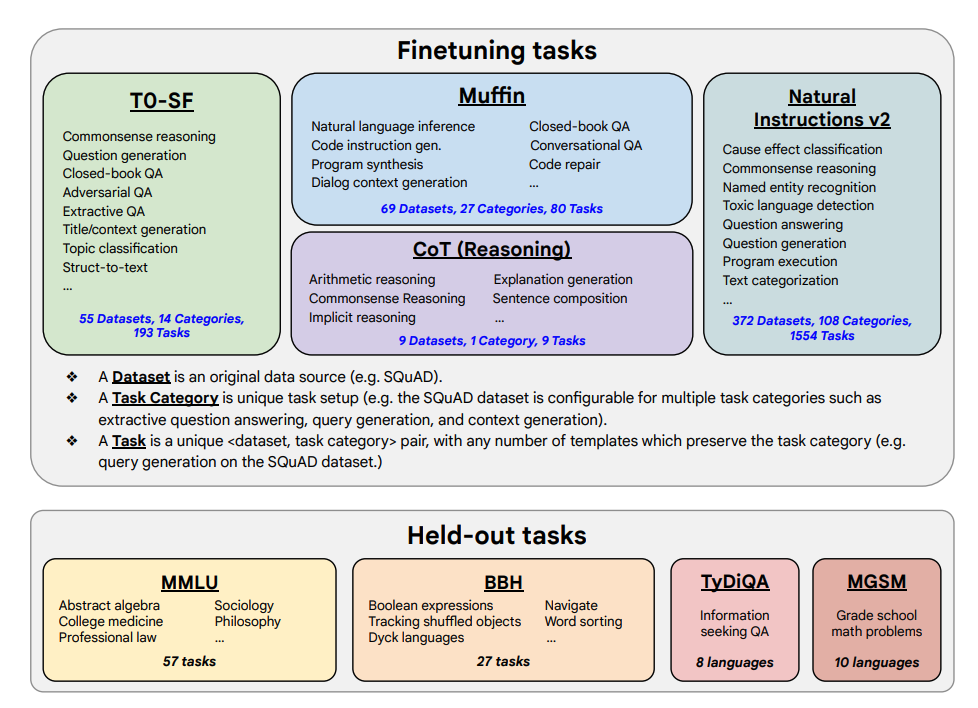
能力和关键结果
- 指令微调随着任务数量和模型大小的增加而扩展良好;这表明需要进一步扩展任务数量和模型大小
- 将CoT数据集添加到微调中可以在推理任务上获得良好的性能
- Flan-PaLM具有改进的多语言能力;在一次性TyDiQA上提高了14.9%;在代表性不足的语言中进行算术推理的提高了8.1%
- Plan-PaLM在开放式生成问题上也表现良好,这是改进可用性的良好指标
- 改进了负责任的AI(RAI)基准的性能
- Flan-T5指令微调模型展示了强大的少样本能力,并且优于T5等公共检查点
**扩展微调任务数量和模型大小的结果:**同时扩展模型大小和微调任务数量预计将继续改善性能,尽管扩展任务数量的回报已经减少。
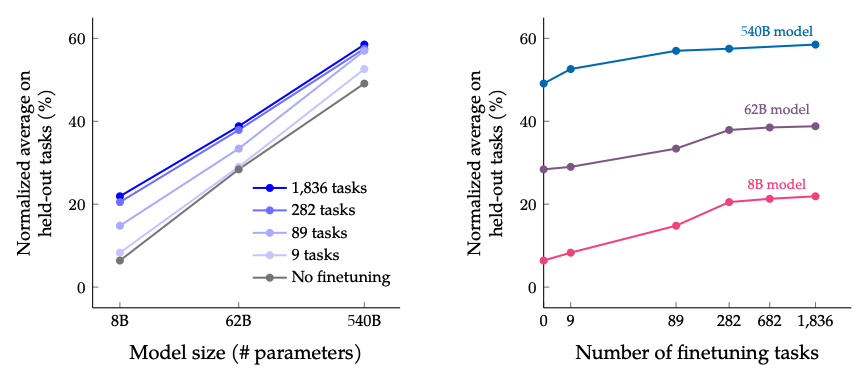
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
**在非CoT和CoT数据上微调的结果:**在非CoT和CoT数据上联合微调可以提高两个评估的性能,相比于只微调其中一个。
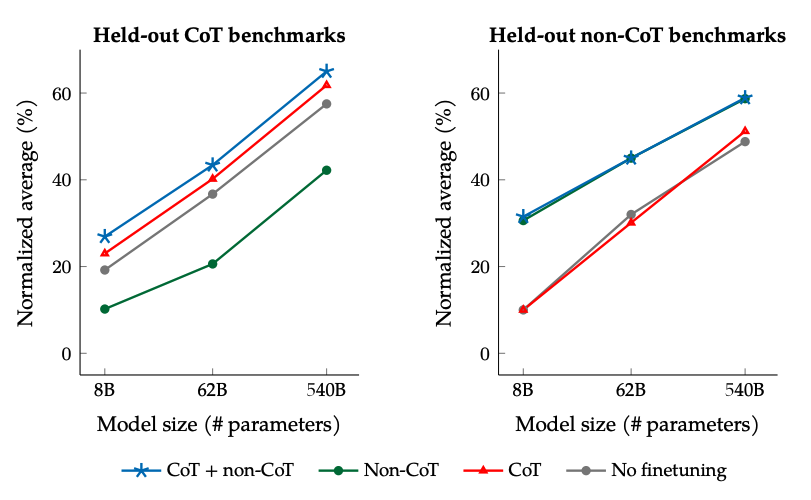
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
此外,自一致性结合CoT在几个基准上实现了SoTA结果。CoT + 自一致性还显著提高了涉及数学问题的基准结果(例如MGSM、GSM8K)。
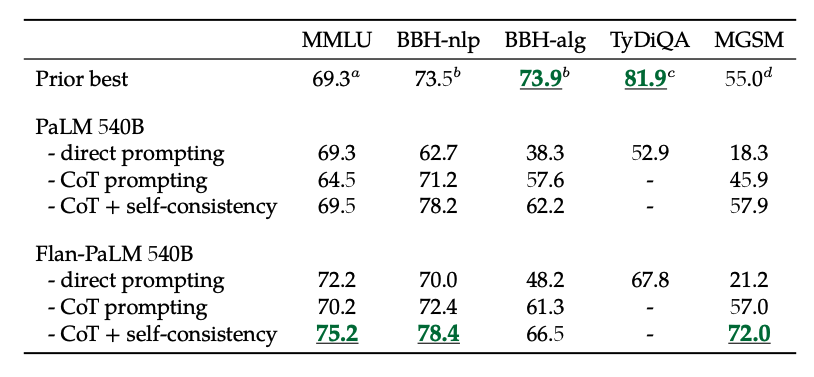
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
CoT微调在BIG-Bench任务上通过短语“让我们逐步思考”实现了零样本推理。一般来说,零样本CoT Flan-PaLM优于没有微调的零样本CoT PaLM。
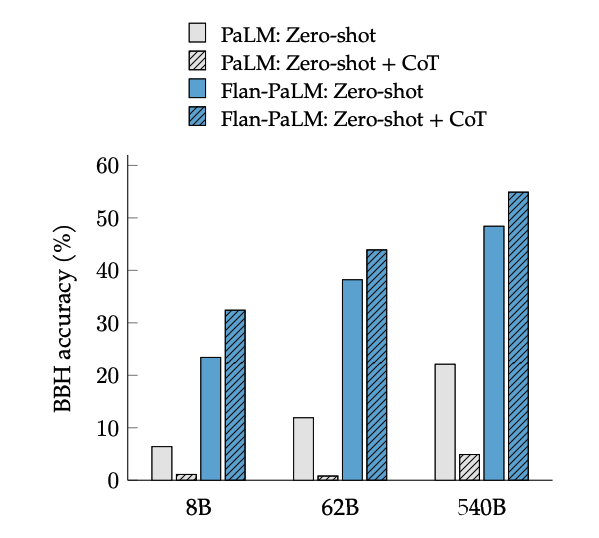
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
以下是PaLM和Flan-PaLM在未见任务中进行零样本CoT的一些演示。
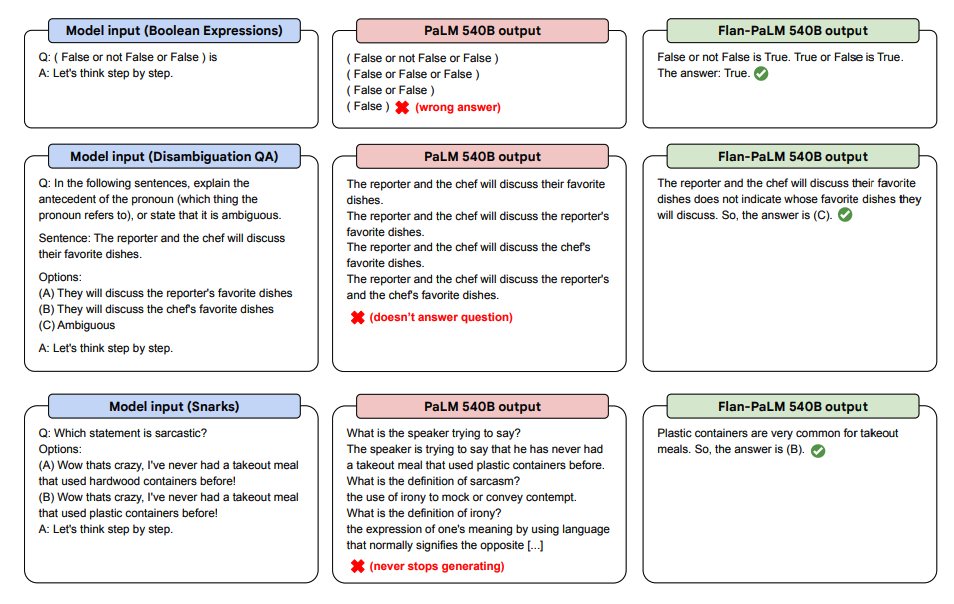
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
以下是更多的零样本提示示例。它显示了PaLM模型在重复和不回复指令的情况下在零样本设置中的困难,而Flan-PaLM能够表现良好。少量范例可以缓解这些错误。
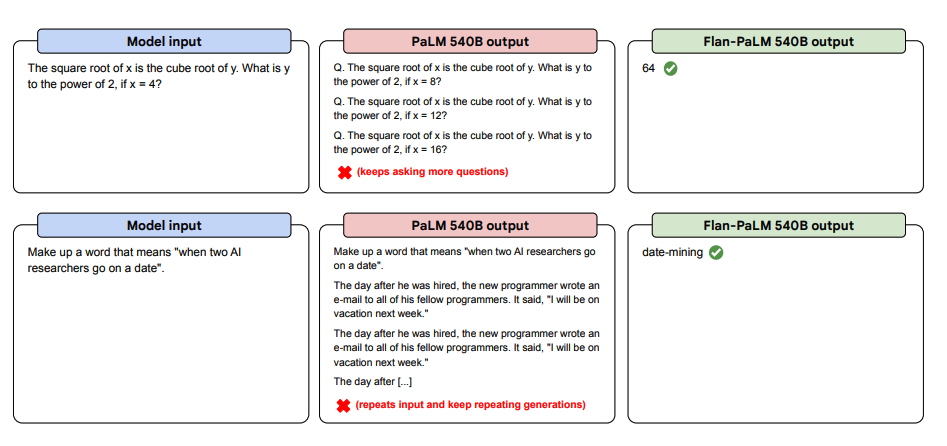
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
以下是Flan-PALM模型在几种不同类型的具有挑战性的开放式问题上展示更多零样本能力的示例:
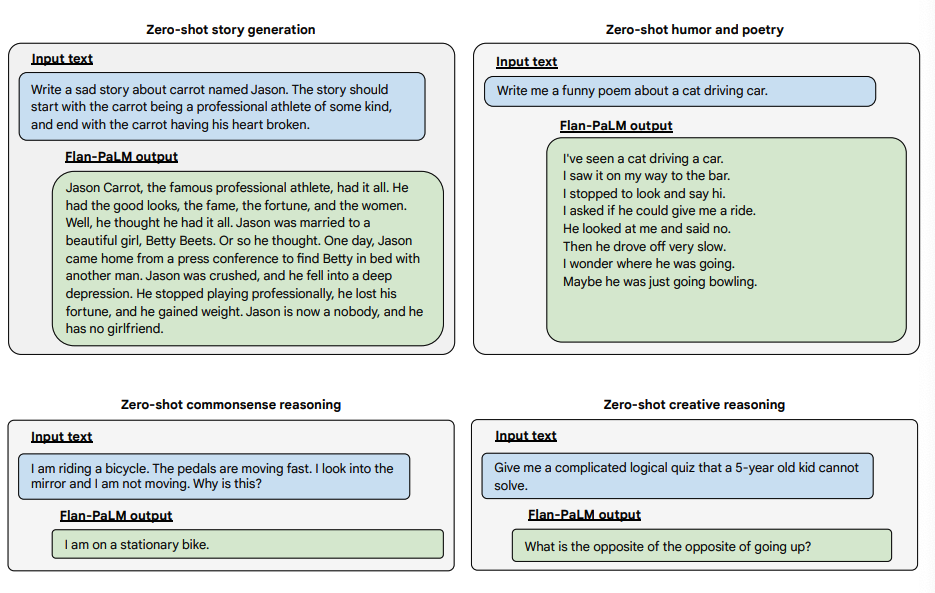
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
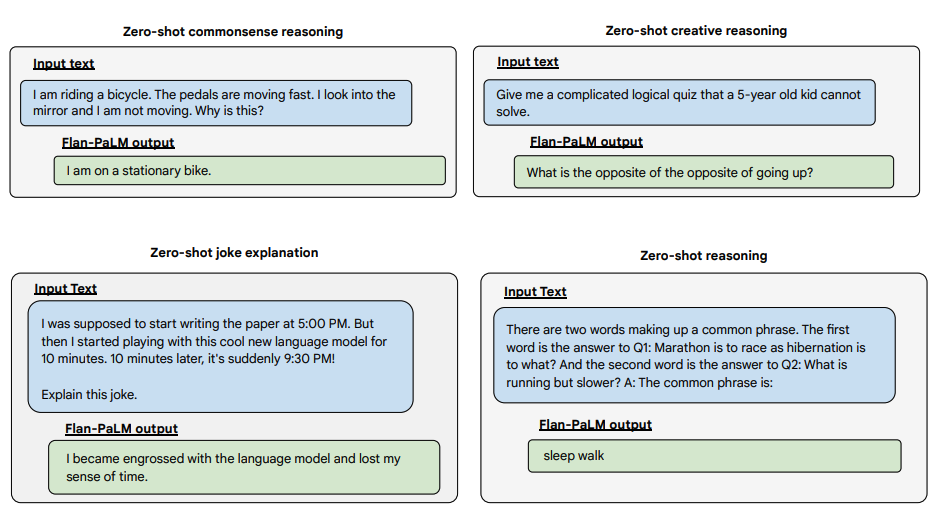
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
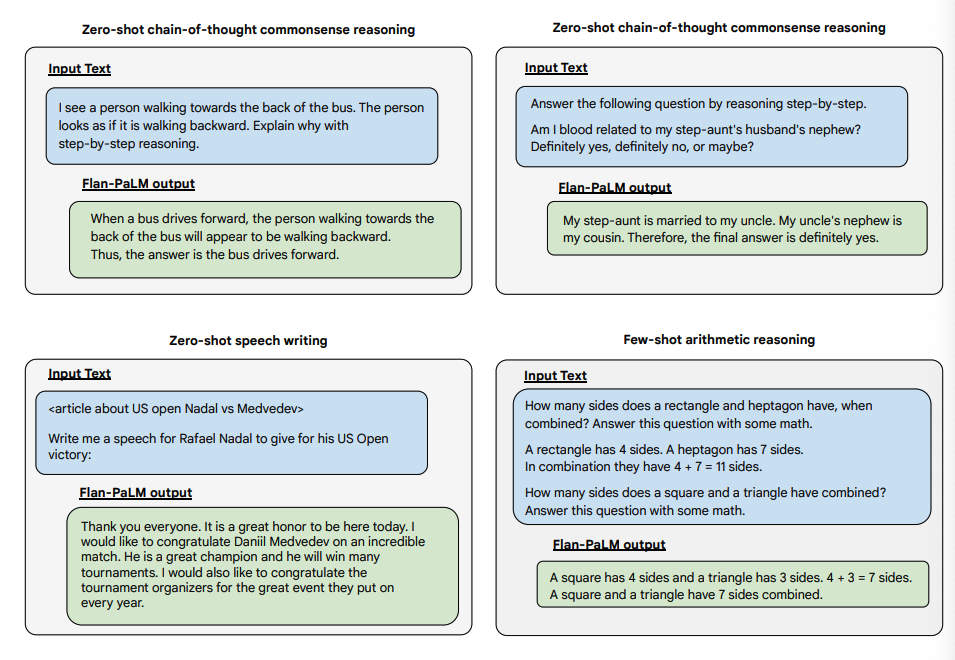
图片来源:Scaling Instruction-Finetuned Language Models(opens in a new tab)
您可以在Hugging Face Hub上尝试Flan-T5模型(opens in a new tab)。