
AIGC 提示词思维树 (ToT)
对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。最近,Yao et el. (2023)(opens in a new tab) 提出了思维树(Tree of Thoughts,ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT 维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LM 能够自己对严谨推理过程的中间思维进行评估。LM 将生成及评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,在系统性探索思维的时候可以向前验证和回溯。
ToT 框架原理如下:
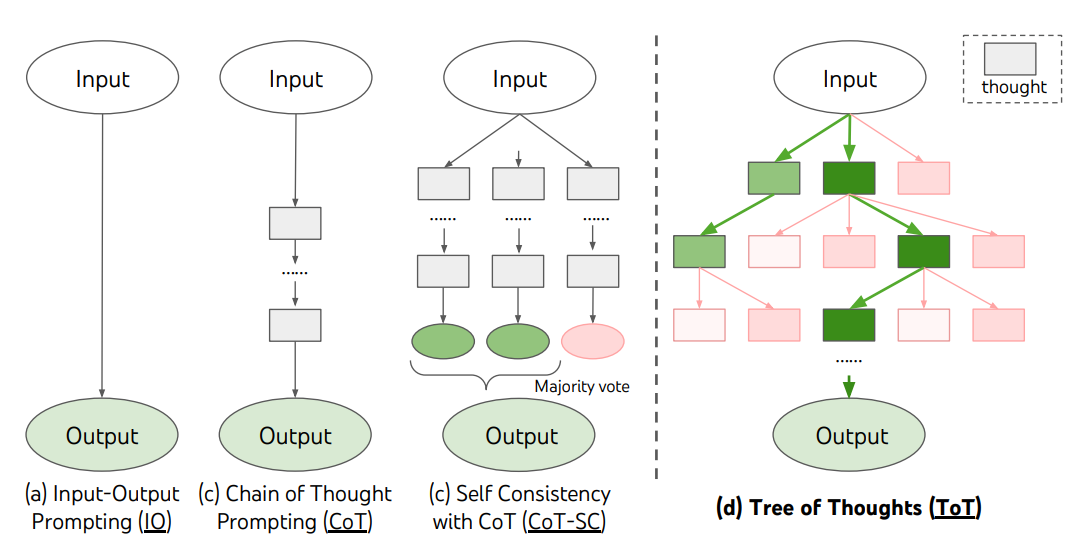
图片援引自:Yao et el. (2023)(opens in a new tab)
ToT 需要针对不同的任务定义思维/步骤的数量以及每步的候选项数量。例如,论文中的“算 24 游戏”是一种数学推理任务,需要分成 3 个思维步骤,每一步都需要一个中间方程。而每个步骤保留最优的(best) 5 个候选项。
ToT 完成算 24 的游戏任务要执行宽度优先搜索(BFS),每步思维的候选项都要求 LM 给出能否得到 24 的评估:“sure/maybe/impossible”(一定能/可能/不可能) 。作者讲到:“目的是得到经过少量向前尝试就可以验证正确(sure)的局部解,基于‘太大/太小’的常识消除那些不可能(impossible)的局部解,其余的局部解作为‘maybe’保留。”每步思维都要抽样得到 3 个评估结果。整个过程如下图所示:
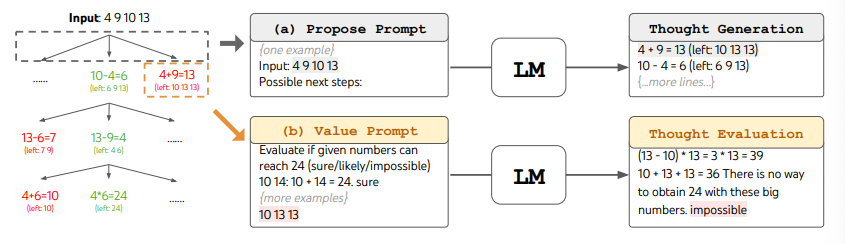
图片援引自:Yao et el. (2023)(opens in a new tab)
从下图中报告的结果来看,ToT 的表现大大超过了其他提示方法:
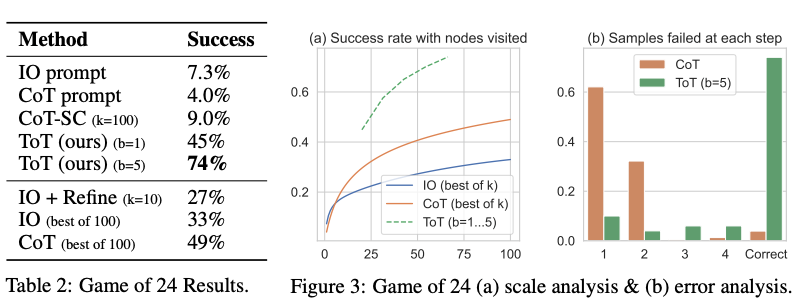
图片援引自:Yao et el. (2023)(opens in a new tab)
这里(opens in a new tab)还有这里(opens in a new tab)可以找到代码例子。
从大方向上来看,Yao et el. (2023)(opens in a new tab) 和 Long (2023)(opens in a new tab) 的核心思路是类似的。两种方法都是以多轮对话搜索树的形式来增强 LLM 解决复杂问题的能力。主要区别在于 Yao et el. (2023)(opens in a new tab) 采用了深度优先(DFS)/广度优先(BFS)/集束(beam)搜索,而 Long (2023)(opens in a new tab) 则提出由强化学习(Reinforcement Learning)训练出的 “ToT 控制器”(ToT Controller)来驱动树的搜索策略(宝库什么时候回退和搜索到哪一级回退等等)。深度优先/广度优先/集束搜索是通用搜索策略,并不针对具体问题。相比之下,由强化学习训练出的 ToT 控制器有可能从新的数据集学习,或是在自对弈(AlphaGo vs. 蛮力搜索)的过程中学习。因此,即使采用的是冻结的 LLM,基于强化学习构建的 ToT 系统仍然可以不断进化,学习新的知识。
Hulbert (2023)(opens in a new tab) 提出了思维树(ToT)提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
假设三位不同的专家来回答这个问题。所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。然后,所有专家都写下他们思考的下一个骤并分享。以此类推,直到所有专家写完他们思考的所有步骤。只要大家发现有专家的步骤出错了,就让这位专家离开。请问...