
PyTorch torch
译者:https : //pytorch.org/docs/stable/torch.html
此外,它提供了许多实用程序,可有效地序列化张量和任意类型,以及其他有用的实用程序。
它具有CUDA对应项,使您能够具有计算能力> = 3.0的NVIDIA GPU上运行张量计算。
张量
torch.is_tensor(obj)¶如果<cite> obj </ cite>是PyTorch张量,则返回True。
参数
obj(对象)–要测试的对象
torch.is_storage(obj)¶如果<cite> obj </ cite>是PyTorch存储对象,则返回True。
参量
obj(对象)–要测试的对象
torch.is_floating_point(input) -> (bool)¶如果input的数据类型是浮点数据类型,即torch.float64,torch.float32和torch.float16之一,则返回True。
参量
输入(tensor)–要测试的PyTorch张量
torch.set_default_dtype(d)¶将默认浮点D型设置为d。类型该用作将 torch.tensor() 中类型推断的默认浮点类型。
默认浮点dtype最初为torch.float32。
参量
d(torch.dtype)–浮点dtype,变为成为值
例:
>>> torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32
torch.float32
>>> torch.set_default_dtype(torch.float64)
>>> torch.tensor([1.2, 3]).dtype # a new floating point tensor
torch.float64torch.get_default_dtype() → torch.dtype¶获取当前的默认浮点数 torch.dtype 。
例:
>>> torch.get_default_dtype() # initial default for floating point is torch.float32
torch.float32
>>> torch.set_default_dtype(torch.float64)
>>> torch.get_default_dtype() # default is now changed to torch.float64
torch.float64
>>> torch.set_default_tensor_type(torch.FloatTensor) # setting tensor type also affects this
>>> torch.get_default_dtype() # changed to torch.float32, the dtype for torch.FloatTensor
torch.float32torch.set_default_tensor_type(t)¶默认将的torch.Tensor类型设置为浮点张量类型t。类型该用作还将 torch.tensor() 中类型推断的默认浮点类型。
默认的浮点张量类型最初为torch.FloatTensor。
参量
t(python:type或同轴)–浮点张量类型类型名称
例:
>>> torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32
torch.float32
>>> torch.set_default_tensor_type(torch.DoubleTensor)
>>> torch.tensor([1.2, 3]).dtype # a new floating point tensor
torch.float64torch.numel(input) → int¶返回input张量中的元素总数。
参量
输入(张量)–输入张量。
例:
>>> a = torch.randn(1, 2, 3, 4, 5)
>>> torch.numel(a)
120
>>> a = torch.zeros(4,4)
>>> torch.numel(a)
16torch.set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, profile=None, sci_mode=None)¶设置打印选项。从NumPy无耻地拿走的物品
参量
- precision –浮点输出的精度位数(默认= 4)。
- 阈值 –触发汇总而不是完整的 <cite>repr</cite> 的数组元素总数(默认= 1000)。
- edgeitems -每个维的开始和结束处摘要中数组项目的数量(默认= 3)。
- 线宽 –用于插入换行符的每行字符数(默认= 80)。 阈值矩阵将忽略此参数。
- 配置文件 – Sane 默认用于漂亮的打印。 可以使用以上任何选项覆盖。 (<cite>默认</cite>,<cite>短</cite>,<cite>完整</cite>中的任何一种)
- sci_mode –启用(真)或禁用(假)科学计数法。 如果指定了 None(默认),则该值由 <cite>_Formatter</cite> 定义
torch.set_flush_denormal(mode) → bool¶禁用 CPU 上的非正常浮点数。
如果您的系统支持刷新非正规数并且已成功配置刷新非正规模式,则返回True。 set_flush_denormal() 仅在支持 SSE3 的 x86 架构上受支持。
Parameters
模式 (bool )–控制是否启用冲洗非正常模式
Example:
>>> torch.set_flush_denormal(True)
True
>>> torch.tensor([1e-323], dtype=torch.float64)
tensor([ 0.], dtype=torch.float64)
>>> torch.set_flush_denormal(False)
True
>>> torch.tensor([1e-323], dtype=torch.float64)
tensor(9.88131e-324 *
[ 1.0000], dtype=torch.float64)创作行动
注意
随机抽样创建操作列在随机抽样下,包括: torch.rand() torch.rand_like() torch.randn() torch.randn_like() torch.randint() torch.randint_like() torch.randperm() 您也可以将 torch.empty() 与输入一起使用
位随机抽样方法来创建 torch.Tensor ,并从更广泛的分布范围内采样值。
torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False) → Tensor¶用data构造一个张量。
警告
torch.tensor() 始终复制data。 如果您具有张量data并希望避免复制,请使用 torch.Tensor.requires_grad_() 或 torch.Tensor.detach() 。 如果您有 NumPy ndarray并想避免复制,请使用 torch.as_tensor() 。
Warning
当数据是张量 <cite>x</cite> 时, torch.tensor() 从传递的任何数据中读出“数据”,并构造一个叶子变量。 因此,torch.tensor(x)等同于x.clone().detach(),torch.tensor(x, requires_grad=True)等同于x.clone().detach().requires_grad_(True)。
建议使用clone()和detach()的等效项。
Parameters
- 数据 (array_like )–张量的初始数据。 可以是列表,元组,NumPy
ndarray,标量和其他类型。 - dtype (
torch.dtype,可选)–返回张量的所需数据类型。 默认值:如果None,则从data推断数据类型。 - 设备 (
torch.device,可选)–返回张量的所需设备。 默认值:如果None,则使用当前设备作为默认张量类型(请参见torch.set_default_tensor_type())。device将是用于 CPU 张量类型的 CPU,并且是用于 CUDA 张量类型的当前 CUDA 设备。 - require_grad (bool , 可选)–如果 autograd 应该在返回的张量上记录操作。 默认值:
False。 - pin_memory (bool , 可选)–如果设置,返回的张量将分配在固定的内存中。 仅适用于 CPU 张量。 默认值:
False。
Example:
>>> torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
tensor([[ 0.1000, 1.2000],
[ 2.2000, 3.1000],
[ 4.9000, 5.2000]])
>>> torch.tensor([0, 1]) # Type inference on data
tensor([ 0, 1])
>>> torch.tensor([[0.11111, 0.222222, 0.3333333]],
dtype=torch.float64,
device=torch.device('cuda:0')) # creates a torch.cuda.DoubleTensor
tensor([[ 0.1111, 0.2222, 0.3333]], dtype=torch.float64, device='cuda:0')
>>> torch.tensor(3.14159) # Create a scalar (zero-dimensional tensor)
tensor(3.1416)
>>> torch.tensor([]) # Create an empty tensor (of size (0,))
tensor([])torch.sparse_coo_tensor(indices, values, size=None, dtype=None, device=None, requires_grad=False) → Tensor¶在给定values和给定values的情况下,以非零元素构造 COO(rdinate)格式的稀疏张量。 稀疏张量可以是<cite>而不是</cite>,在那种情况下,索引中有重复的坐标,并且该索引处的值是所有重复值条目的总和: torch.sparse 。
Parameters
- 索引 (array_like )–张量的初始数据。 可以是列表,元组,NumPy
ndarray,标量和其他类型。 将在内部强制转换为torch.LongTensor。 索引是矩阵中非零值的坐标,因此应为二维,其中第一维是张量维数,第二维是非零值数。 - 值 (array_like )–张量的初始值。 可以是列表,元组,NumPy
ndarray,标量和其他类型。 - 大小(列表,元组或
torch.Size,可选)–稀疏张量的大小。 如果未提供,则将推断大小为足以容纳所有非零元素的最小大小。 - dtype (torch.dtype ,可选)–返回张量的所需数据类型。默认值:如果为 None,则从
values推断数据类型。 - 设备 (torch.device ,可选)–返回张量的所需设备。 默认值:如果为 None,则使用当前设备作为默认张量类型(请参见 torch.set_default_tensor_type())。
device将是用于 CPU 张量类型的 CPU,是用于 CUDA 张量类型的当前 CUDA 设备。 - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> i = torch.tensor([[0, 1, 1],
[2, 0, 2]])
>>> v = torch.tensor([3, 4, 5], dtype=torch.float32)
>>> torch.sparse_coo_tensor(i, v, [2, 4])
tensor(indices=tensor([[0, 1, 1],
[2, 0, 2]]),
values=tensor([3., 4., 5.]),
size=(2, 4), nnz=3, layout=torch.sparse_coo)
>>> torch.sparse_coo_tensor(i, v) # Shape inference
tensor(indices=tensor([[0, 1, 1],
[2, 0, 2]]),
values=tensor([3., 4., 5.]),
size=(2, 3), nnz=3, layout=torch.sparse_coo)
>>> torch.sparse_coo_tensor(i, v, [2, 4],
dtype=torch.float64,
device=torch.device('cuda:0'))
tensor(indices=tensor([[0, 1, 1],
[2, 0, 2]]),
values=tensor([3., 4., 5.]),
device='cuda:0', size=(2, 4), nnz=3, dtype=torch.float64,
layout=torch.sparse_coo)
## Create an empty sparse tensor with the following invariants:
## 1\. sparse_dim + dense_dim = len(SparseTensor.shape)
## 2\. SparseTensor._indices().shape = (sparse_dim, nnz)
## 3\. SparseTensor._values().shape = (nnz, SparseTensor.shape[sparse_dim:])
#
## For instance, to create an empty sparse tensor with nnz = 0, dense_dim = 0 and
## sparse_dim = 1 (hence indices is a 2D tensor of shape = (1, 0))
>>> S = torch.sparse_coo_tensor(torch.empty([1, 0]), [], [1])
tensor(indices=tensor([], size=(1, 0)),
values=tensor([], size=(0,)),
size=(1,), nnz=0, layout=torch.sparse_coo)
## and to create an empty sparse tensor with nnz = 0, dense_dim = 1 and
## sparse_dim = 1
>>> S = torch.sparse_coo_tensor(torch.empty([1, 0]), torch.empty([0, 2]), [1, 2])
tensor(indices=tensor([], size=(1, 0)),
values=tensor([], size=(0, 2)),
size=(1, 2), nnz=0, layout=torch.sparse_coo)torch.as_tensor(data, dtype=None, device=None) → Tensor¶将数据转换为<cite>torch。张量</cite>。 如果数据已经是具有相同 <cite>dtype</cite> 和<cite>设备</cite>的<cite>张量</cite>,则不会执行任何复制,否则将使用新的<cite>张量</cite>。 如果数据<cite>张量</cite>>具有requires_grad=True,则返回保留计算图的计算图。
同样,如果数据是对应的 <cite>dtype</cite> 的ndarray,并且<cite>设备</cite>是 cpu,则不会执行任何复制。
Parameters
- data (array_like) – Initial data for the tensor. Can be a list, tuple, NumPy
ndarray,scalar, and other types. - dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, infers data type fromdata. - device(
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types.
Example:
>>> a = numpy.array([1, 2, 3])
>>> t = torch.as_tensor(a)
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([-1, 2, 3])
>>> a = numpy.array([1, 2, 3])
>>> t = torch.as_tensor(a, device=torch.device('cuda'))
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([1, 2, 3])torch.as_strided(input, size, stride, storage_offset=0) → Tensor¶创建具有指定size,stride和storage_offset的现有<cite>炬管</cite> input的视图。
Warning
创建的张量中的一个以上元素可以引用单个存储位置。 结果,就地操作(尤其是矢量化的操作)可能会导致错误的行为。 如果需要写张量,请先克隆它们。
许多 PyTorch 函数可返回张量视图,并在此函数内部实现。 这些功能,例如 torch.Tensor.expand() ,更易于阅读,因此更可取。
Parameters
- input (Tensor) – the input tensor.
- 大小(元组 或 python:ints )–输出张量的形状
- 跨度(元组 或 python:ints )–输出张量的跨度
- storage_offset (python:int , 可选)–输出张量的基础存储中的偏移量
Example:
>>> x = torch.randn(3, 3)
>>> x
tensor([[ 0.9039, 0.6291, 1.0795],
[ 0.1586, 2.1939, -0.4900],
[-0.1909, -0.7503, 1.9355]])
>>> t = torch.as_strided(x, (2, 2), (1, 2))
>>> t
tensor([[0.9039, 1.0795],
[0.6291, 0.1586]])
>>> t = torch.as_strided(x, (2, 2), (1, 2), 1)
tensor([[0.6291, 0.1586],
[1.0795, 2.1939]])torch.from_numpy(ndarray) → Tensor¶从numpy.ndarray创建 Tensor 。
返回的张量和ndarray共享相同的内存。 对张量的修改将反映在ndarray中,反之亦然。 返回的张量不可调整大小。
当前它接受具有numpy.float64,numpy.float32,numpy.float16,numpy.int64,numpy.int32,
numpy.int16,numpy.int8,numpy.uint8和numpy.bool d 类型的ndarray。
Example:
>>> a = numpy.array([1, 2, 3])
>>> t = torch.from_numpy(a)
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([-1, 2, 3])torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回一个由标量值 <cite>0</cite> 填充的张量,其形状由变量参数size定义。
Parameters
- 大小 (python:int ... )–定义输出张量形状的整数序列。 可以是可变数量的参数,也可以是列表或元组之类的集合。
- 输出 (tensor , 可选)–输出张量。
- dtype (
torch.dtype,可选)–返回张量的所需数据类型。 默认值:如果None使用全局默认值(请参见torch.set_default_tensor_type())。 - 布局 (
torch.layout,可选)–返回的 Tensor 所需的布局。 默认值:torch.strided。 - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor.Default:
False.
Example:
>>> torch.zeros(2, 3)
tensor([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> torch.zeros(5)
tensor([ 0., 0., 0., 0., 0.])torch.zeros_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor¶返回一个由标量值 <cite>0</cite> 填充的张量,其大小与input相同。 torch.zeros_like(input)等效于torch.zeros(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)。
Warning
从 0.4 开始,此功能不支持out关键字。 作为替代,旧的torch.zeros_like(input, out=output)等效于torch.zeros(input.size(), out=output)。
Parameters
- 输入 (tensor)–
input的大小将确定输出张量的大小。 - dtype (
torch.dtype,可选)–返回的 Tensor 的所需数据类型。 默认值:如果为None,则默认为input的dtype。 - 布局 (
torch.layout,可选)–返回张量的所需布局。 默认值:如果为None,则默认为input的布局。 - 设备 (
torch.device,可选)–返回张量的所需设备。 默认值:如果为None,则默认为input的设备。 - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Defaultt:
False.
Example:
>>> input = torch.empty(2, 3)
>>> torch.zeros_like(input)
tensor([[ 0., 0., 0.],
[ 0., 0., 0.]])torch.ones(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回一个由标量值 <cite>1</cite> 填充的张量,其形状由变量自变量size定义。
Parameters
- size (python:int...) – a sequence of integers defining the shape of the output tensor. Can be a variable number of arguments or a collection like a list or tuple.
- out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device(
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.ones(2, 3)
tensor([[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> torch.ones(5)
tensor([ 1., 1., 1., 1., 1.])torch.ones_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor¶返回一个由标量值 <cite>1</cite> 填充的张量,其大小与input相同。 torch.ones_like(input)等效于torch.ones(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)。
Warning
从 0.4 开始,此功能不支持out关键字。 作为替代,旧的torch.ones_like(input, out=output)等效于torch.ones(input.size(), out=output)。
Parameters
- input (Tensor) – the size of
inputwill determine size of the output tensor. - dtype(
torch.dtype, optional) – the desired data type of returned Tensor. Default: ifNone, defaults to the dtype ofinput. - layout(
torch.layout, optional)– the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device (
torch.device, optional)– the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor.Default:
False
Example:
>>> input = torch.empty(2, 3)
>>> torch.ones_like(input)
tensor([[ 1., 1., 1.],
[ 1., 1., 1.]])torch.arange(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回大小为
 的一维张量,该值具有从<cite>开始</cite>开始具有公共差
的一维张量,该值具有从<cite>开始</cite>开始具有公共差step的间隔[start, end)的值。
请注意,与end比较时,非整数step会出现浮点舍入错误; 为了避免不一致,在这种情况下,建议在end中添加一个小的ε。

Parameters
- 起始(编号)–点集的起始值。 默认值:
0。 - 结束(编号)–点集的结束值
- 步骤(编号)–每对相邻点之间的间隙。 默认值:
1。 - out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype,可选)–返回张量的所需数据类型。 默认值:如果None使用全局默认值(请参阅torch.set_default_tensor_type())。 如果未提供 <cite>dtype</cite> ,则从其他输入参数推断数据类型。 如果<cite>开始</cite>,<cite>结束</cite>或<cite>停止</cite>中的任何一个是浮点,则推断 <cite>dtype</cite> 为默认 dtype,请参见[get_default_dtype()。 否则,将 <cite>dtype</cite> 推断为 <cite>torch.int64</cite> 。 - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default
False.
Example:
>>> torch.arange(5)
tensor([ 0, 1, 2, 3, 4])
>>> torch.arange(1, 4)
tensor([ 1, 2, 3])
>>> torch.arange(1, 2.5, 0.5)
tensor([ 1.0000, 1.5000, 2.0000])torch.range(start=0, end, step=1, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶在步骤step中返回大小为
 的一维张量,其值从
的一维张量,其值从start到end。 阶跃是张量中两个值之间的差距。
Warning
不推荐使用此功能,而推荐使用 torch.arange() 。
Parameters
- start (python:float )–点集的起始值。 默认值:
0。 - end (python:float )–点集的结束值
- 步骤 (python:float )–每对相邻点之间的间隙。 默认值:
1。 - out (Tensor, optional) – the output tensor.
- dtype(
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). If <cite>dtype</cite> is not given, infer the data type from the other input arguments. If any of <cite>start</cite>, <cite>end</cite>, or <cite>stop</cite> are floating-point, the <cite>dtype</cite> is inferred to be the default dtype, seeget_default_dtype(). Otherwise, the <cite>dtype</cite> is inferred to be <cite>torch.int64</cite>. - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default: torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.range(1, 4)
tensor([ 1., 2., 3., 4.])
>>> torch.range(1, 4, 0.5)
tensor([ 1.0000, 1.5000, 2.0000, 2.5000, 3.0000, 3.5000, 4.0000])torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回start和end之间等距点的steps的一维张量。
输出张量为steps大小的 1-D。
Parameters
- 开始 (python:float )–点集的起始值
- end (python:float) – the ending value for the set of points
- 步骤 (python:int )–在
start和end之间采样的点数。 默认值:100。 - out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.linspace(3, 10, steps=5)
tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])
>>> torch.linspace(-10, 10, steps=5)
tensor([-10., -5., 0., 5., 10.])
>>> torch.linspace(start=-10, end=10, steps=5)
tensor([-10., -5., 0., 5., 10.])
>>> torch.linspace(start=-10, end=10, steps=1)
tensor([-10.])torch.logspace(start, end, steps=100, base=10.0, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回与
 和
和
 之间的底数
之间的底数base对数间隔的steps点的一维张量。
The output tensor is 1-D of size steps.
Parameters
- start (python:float) – the starting value for the set of points
- end (python:float) – the ending value for the set of points
- steps (python:int) – number of points to sample between
startandend. Default:100. - 基数 (python:float )–对数函数的基数。 默认值:
10.0。 - out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.logspace(start=-10, end=10, steps=5)
tensor([ 1.0000e-10, 1.0000e-05, 1.0000e+00, 1.0000e+05, 1.0000e+10])
>>> torch.logspace(start=0.1, end=1.0, steps=5)
tensor([ 1.2589, 2.1135, 3.5481, 5.9566, 10.0000])
>>> torch.logspace(start=0.1, end=1.0, steps=1)
tensor([1.2589])
>>> torch.logspace(start=2, end=2, steps=1, base=2)
tensor([4.0])torch.eye(n, m=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回一个二维张量,对角线上有一个,其他位置为零。
Parameters
- n (python:int )–行数
- m (python:int , 可选)–默认为n的列数
- out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
退货
二维张量,对角线上有一个,其他位置为零
返回类型
张量
Example:
>>> torch.eye(3)
tensor([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])torch.empty(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False) → Tensor¶返回填充有未初始化数据的张量。 张量的形状由变量参数size定义。
Parameters
- size (python:int...) – a sequence of integers defining the shape of the output tensor. Can be a variable number of arguments or a collection like a list or tuple.
- out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()).
- layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided.
- device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False. - pin_memory (bool__, optional) – If set, returned tensor would be allocated in the pinned memory. Works only for CPU tensors. Default:
False.
Example:
>>> torch.empty(2, 3)
tensor(1.00000e-08 *
[[ 6.3984, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000]])torch.empty_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor¶返回与input相同大小的未初始化张量。 torch.empty_like(input)等效于torch.empty(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)。
Parameters
- input (Tensor) – the size of
inputwill determine size of the output tensor. - dtype (torch.dtype, optional) – the desired data type of returned Tensor. Default: if None, defaults to the dtype of input.
- layout (
torch.layout, optional) – the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device(
torch.device, optional) – the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad (bool__, optional) – If autograd should record operations on the returned Default:
False.
Example:
>>> torch.empty((2,3), dtype=torch.int64)
tensor([[ 9.4064e+13, 2.8000e+01, 9.3493e+13],
[ 7.5751e+18, 7.1428e+18, 7.5955e+18]])torch.empty_strided(size, stride, dtype=None, layout=None, device=None, requires_grad=False, pin_memory=False) → Tensor¶返回填充有未初始化数据的张量。 张量的形状和步幅分别由变量参数size和stride定义。 torch.empty_strided(size, stride)等同于torch.empty(size).as_strided(size, stride)。
Warning
创建的张量中的一个以上元素可以引用单个存储位置。 结果,就地操作(尤其是矢量化的操作)可能会导致错误的行为。 如果需要写张量,请先克隆它们。
Parameters
- 大小(python:ints 的元组)–输出张量的形状
- 跨度(python:ints 的元组)–输出张量的跨度
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False. - pin_memory (bool__, optional) – If set, returned tensor would be allocated in the pinned memory. Works only for CPU tensors. Default:
False.
Example:
>>> a = torch.empty_strided((2, 3), (1, 2))
>>> a
tensor([[8.9683e-44, 4.4842e-44, 5.1239e+07],
[0.0000e+00, 0.0000e+00, 3.0705e-41]])
>>> a.stride()
(1, 2)
>>> a.size()
torch.Size([2, 3])torch.full(size, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回大小为size的张量,其中填充了fill_value。
Parameters
- 大小 (python:int ... )–定义输出张量形状的整数列表,元组或
torch.Size。 - fill_value –用来填充输出张量的数字。
- out (Tenso, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()).
- layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided.
- device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types.
- requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.full((2, 3), 3.141592)
tensor([[ 3.1416, 3.1416, 3.1416],
[ 3.1416, 3.1416, 3.1416]])torch.full_like(input, fill_value, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回与填充有fill_value的input大小相同的张量。 torch.full_like(input, fill_value)等同于torch.full(input.size(), fill_value, dtype=input.dtype, layout=input.layout, device=input.device)。
Parameters
- input (Tensor) – the size of input will determine size of the output tensor.
- fill_value – the number to fill the output tensor with.
- dtype (
torch.dtype, optional) – the desired data type of returned Tensor. Default: ifNone, defaults to the dtype ofinput. - layout (
torch.layout, optional) – the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad(bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
torch.quantize_per_tensor(input, scale, zero_point, dtype) → Tensor¶将浮点张量转换为具有给定比例和零点的量化张量。
Parameters
- 输入 (tensor)–浮点张量进行量化
- 标度 (python:float )–适用于量化公式的标度
- zero_point (python:int )–映射为浮点零的整数值偏移
- dtype (
torch.dtype)–返回张量的所需数据类型。 必须是量化的 dtypes 之一:torch.quint8,torch.qint8和torch.qint32
Returns
新量化的张量
Return type
Tensor
Example:
>>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8)
tensor([-1., 0., 1., 2.], size=(4,), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=0.1, zero_point=10)
>>> torch.quantize_per_tensor(torch.tensor([-1.0, 0.0, 1.0, 2.0]), 0.1, 10, torch.quint8).int_repr()
tensor([ 0, 10, 20, 30], dtype=torch.uint8)torch.quantize_per_channel(input, scales, zero_points, axis, dtype) → Tensor¶将浮点张量转换为具有给定比例和零点的每通道量化张量。
Parameters
- input (Tensor) – float tensor to quantize
- 秤 (tensor)–要使用的一维浮标秤,尺寸应匹配
input.size(axis) - zero_points (python:int )–要使用的整数 1D 张量偏移量,大小应与
input.size(axis)相匹配 - 轴 (python:int )–应用每个通道量化的维度
- dtype (
torch.dtype) – the desired data type of returned tensor. Has to be one of the quantized dtypes:torch.quint8,torch.qint8,torch.qint32
Returns
A newly quantized tensor
Return type
Tensor
Example:
>>> x = torch.tensor([[-1.0, 0.0], [1.0, 2.0]])
>>> torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8)
tensor([[-1., 0.],
[ 1., 2.]], size=(2, 2), dtype=torch.quint8,
quantization_scheme=torch.per_channel_affine,
scale=tensor([0.1000, 0.0100], dtype=torch.float64),
zero_point=tensor([10, 0]), axis=0)
>>> torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8).int_repr()
tensor([[ 0, 10],
[100, 200]], dtype=torch.uint8)索引,切片,联接,操作变更
torch.cat(tensors, dim=0, out=None) → Tensor¶在给定维度上连接seq张量的给定序列。 所有张量必须具有相同的形状(在连接维中除外)或为空。
torch.cat() 可以看作是 torch.split() 和 torch.chunk()
的逆运算。
通过示例可以更好地理解 torch.cat() 。
Parameters
- 张量(张量序列)–同一类型的任何 python 张量序列。 提供的非空张量必须具有相同的形状,但猫的尺寸除外。
- 暗淡的 (python:int , 可选)–张量级联的尺寸
- out (Tensor, optional) – the output tensor.
Example:
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,
-1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,
-0.5790, 0.1497]])torch.chunk(input, chunks, dim=0) → List of Tensors¶将张量拆分为特定数量的块。
如果沿给定维度dim的张量大小不能被chunks整除,则最后一块将较小。
Parameters
- 输入 (tensor)–要分割的张量
- 块 (python:int )–要返回的块数
- 暗淡的 (python:int )–沿其张量分裂的尺寸
torch.gather(input, dim, index, out=None, sparse_grad=False) → Tensor¶沿<cite>昏暗</cite>指定的轴收集值。
对于 3-D 张量,输出指定为:
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2如果input是大小为
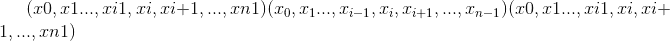 和
和dim = i的 n 维张量,则index必须是大小为
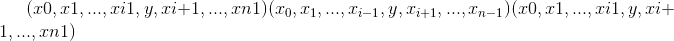 的
的
 -维张量,其中
-维张量,其中
 和
和out具有相同的大小 大小为index。
Parameters
- 输入 (tensor)–源张量
- 暗淡的 (python:int )–沿其索引的轴
- 索引 (LongTensor )–要收集的元素的索引
- 输出 (tensor , 可选)–目标张量
- sparse_grad (bool , 可选)–如果
True,则梯度 w.r.t.input将是一个稀疏张量。
Example:
>>> t = torch.tensor([[1,2],[3,4]])
>>> torch.gather(t, 1, torch.tensor([[0,0],[1,0]]))
tensor([[ 1, 1],
[ 4, 3]])torch.index_select(input, dim, index, out=None) → Tensor¶返回一个新张量,该张量使用index LongTensor 中的index中的条目沿维度dim索引input张量。
返回的张量具有与原始张量(input)相同的维数。 dim的尺寸与index的长度相同; 其他尺寸与原始张量中的尺寸相同。
Note
返回的张量不与原始张量使用相同的存储空间而不是。 如果out的形状与预期的形状不同,我们将默默地将其更改为正确的形状,并在必要时重新分配基础存储。
Parameters
- input (Tensor) – the input tensor.
- 暗淡的 (python:int )–我们索引的维度
- 索引 (LongTensor )–包含要索引的索引的一维张量
- out (Tensor, optional) – the output tensor.
Example:
>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
[-0.4664, 0.2647, -0.1228, -1.1068],
[-1.1734, -0.6571, 0.7230, -0.6004]])
>>> indices = torch.tensor([0, 2])
>>> torch.index_select(x, 0, indices)
tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
[-1.1734, -0.6571, 0.7230, -0.6004]])
>>> torch.index_select(x, 1, indices)
tensor([[ 0.1427, -0.5414],
[-0.4664, -0.1228],
[-1.1734, 0.7230]])torch.masked_select(input, mask, out=None) → Tensor¶返回一个新的一维张量,该张量根据布尔值掩码mask为其 <cite>BoolTensor</cite> 索引input张量。
mask张量和input张量的形状不需要匹配,但它们必须是>可广播的。
Note
返回的张量是否而不是使用与原始张量相同的存储
Parameters
- input (Tensor) – the input tensor.
- 掩码 (ByteTensor )–包含二进制掩码的张量,以使用
- out (Tensor, optional) – the output tensor.
Example:
>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.3552, -2.3825, -0.8297, 0.3477],
[-1.2035, 1.2252, 0.5002, 0.6248],
[ 0.1307, -2.0608, 0.1244, 2.0139]])
>>> mask = x.ge(0.5)
>>> mask
tensor([[False, False, False, False],
[False, True, True, True],
[False, False, False, True]])
>>> torch.masked_select(x, mask)
tensor([ 1.2252, 0.5002, 0.6248, 2.0139])torch.narrow(input, dim, start, length) → Tensor¶返回一个新的张量,该张量是input张量的缩小版本。 尺寸dim从start输入到start + length。 返回的张量和input张量共享相同的基础存储。
Parameters
- 输入 (tensor)–张量变窄
- 暗淡的 (python:int )–缩小范围
- 开始 (python:int )–起始尺寸
- 长度 (python:int )–到最终尺寸的距离
Example:
>>> x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> torch.narrow(x, 0, 0, 2)
tensor([[ 1, 2, 3],
[ 4, 5, 6]])
>>> torch.narrow(x, 1, 1, 2)
tensor([[ 2, 3],
[ 5, 6],
[ 8, 9]])torch.nonzero(input, *, out=None, as_tuple=False) → LongTensor or tuple of LongTensors¶
Note
torch.nonzero(..., as_tuple=False) (默认值)返回一个二维张量,其中每一行都是非零值的索引。
torch.nonzero(..., as_tuple=True) 返回一维索引张量的元组,允许进行高级索引,因此x[x.nonzero(as_tuple=True)]给出张量x的所有非零值。 在返回的元组中,每个索引张量都包含特定维度的非零索引。
有关这两种行为的更多详细信息,请参见下文。
当 as_tuple 为“ False”(默认)时:
返回一个张量,该张量包含input所有非零元素的索引。 结果中的每一行都包含input中非零元素的索引。 结果按字典顺序排序,最后一个索引更改最快(C 样式)。
如果input具有
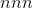 尺寸,则所得索引张量
尺寸,则所得索引张量out的大小为
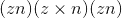 ,其中
,其中
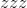 是
是input张量中非零元素的总数。
当 as_tuple 为“ True” 时:
返回一维张量的元组,在input中每个维度一个张量,每个张量包含input所有非零元素的索引(在该维度中)。
如果input具有
 尺寸,则生成的元组包含
尺寸,则生成的元组包含
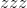 大小的
大小的
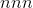 张量,其中
张量,其中
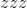 是
是input张量中非零元素的总数。
作为一种特殊情况,当input具有零维和非零标量值时,会将其视为具有一个元素的一维张量。
Parameters
- input (Tensor) – the input tensor.
- out (LongTensor , 可选)–包含索引的输出张量
Returns
如果as_tuple为False,则包含索引的输出张量。 如果as_tuple为True,则每个维度都有一个 1-D 张量,其中包含沿着该维度的每个非零元素的索引。
Return type
LongTensor 或 LongTensor 的元组
Example:
>>> torch.nonzero(torch.tensor([1, 1, 1, 0, 1]))
tensor([[ 0],
[ 1],
[ 2],
[ 4]])
>>> torch.nonzero(torch.tensor([[0.6, 0.0, 0.0, 0.0],
[0.0, 0.4, 0.0, 0.0],
[0.0, 0.0, 1.2, 0.0],
[0.0, 0.0, 0.0,-0.4]]))
tensor([[ 0, 0],
[ 1, 1],
[ 2, 2],
[ 3, 3]])
>>> torch.nonzero(torch.tensor([1, 1, 1, 0, 1]), as_tuple=True)
(tensor([0, 1, 2, 4]),)
>>> torch.nonzero(torch.tensor([[0.6, 0.0, 0.0, 0.0],
[0.0, 0.4, 0.0, 0.0],
[0.0, 0.0, 1.2, 0.0],
[0.0, 0.0, 0.0,-0.4]]), as_tuple=True)
(tensor([0, 1, 2, 3]), tensor([0, 1, 2, 3]))
>>> torch.nonzero(torch.tensor(5), as_tuple=True)
(tensor([0]),)torch.reshape(input, shape) → Tensor¶返回具有与input相同的数据和元素数量,但具有指定形状的张量。 如果可能,返回的张量将是input的视图。 否则,它将是副本。 连续输入和具有兼容步幅的输入可以在不复制的情况下进行重塑,但是您不应该依赖复制与查看行为。
当可以返回视图时,请参见 torch.Tensor.view() 。
单个尺寸可能为-1,在这种情况下,它是根据input中的其余尺寸和元素数量推断出来的。
Parameters
- 输入 (tensor)–要重塑的张量
- 形状 (python:ints 的元组)–新形状
Example:
>>> a = torch.arange(4.)
>>> torch.reshape(a, (2, 2))
tensor([[ 0., 1.],
[ 2., 3.]])
>>> b = torch.tensor([[0, 1], [2, 3]])
>>> torch.reshape(b, (-1,))
tensor([ 0, 1, 2, 3])torch.split(tensor, split_size_or_sections, dim=0)¶将张量拆分为多个块。
如果split_size_or_sections是整数类型,则 tensor 将被拆分为大小相等的块(如果可能)。 如果沿给定维度dim的张量大小不能被split_size整除,则最后一个块将较小。
如果split_size_or_sections是列表,则根据split_size_or_sections将 tensor 拆分为dim,大小为dim。
Parameters
- 张量 (tensor)–张量分裂。
- split_size_or_sections (python:int )或 ( 列表 ( python :int ))–单个块的大小或每个块的大小列表
- 暗淡的 (python:int )–沿其张量分裂的尺寸。
torch.squeeze(input, dim=None, out=None) → Tensor¶返回一个张量,其中所有尺寸为 <cite>1</cite> 的input尺寸均被删除。
例如,如果<cite>输入</cite>的形状为:
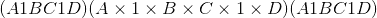 ,则张量中的<cite>张量将为:
,则张量中的<cite>张量将为:
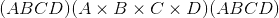 。</cite>
。</cite>
给定dim时,仅在给定尺寸上执行挤压操作。 如果<cite>输入</cite>的形状为:
 ,
,squeeze(input, 0)保持张量不变,但是squeeze(input, 1)会将张量压缩为
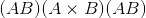 形状。
形状。
Note
返回的张量与输入张量共享存储,因此更改一个张量的内容将更改另一个张量的内容。
Parameters
- input (Tensor) – the input tensor.
- 暗淡的 (python:int , 可选)–如果给定,则仅在此维度上压缩输入
- out (Tensor, optional) – the output tensor.
Example:
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])torch.stack(tensors, dim=0, out=None) → Tensor¶将张量的序列沿新维度连接起来。
所有张量都必须具有相同的大小。
Parameters
- 张量(张量序列)–连接的张量序列
- 暗淡的 (python:int )–插入的尺寸。 必须介于 0 和级联张量的维数之间(含)
- out (Tensor, optional) – the output tensor.
torch.t(input) → Tensor¶期望input为< = 2-D 张量,并转置尺寸 0 和 1。
将按原样返回 0-D 和 1-D 张量,并且可以将 2-D 张量视为transpose(input, 0, 1)的简写函数。
Parameters
input (Tensor) – the input tensor.
Example:
>>> x = torch.randn(())
>>> x
tensor(0.1995)
>>> torch.t(x)
tensor(0.1995)
>>> x = torch.randn(3)
>>> x
tensor([ 2.4320, -0.4608, 0.7702])
>>> torch.t(x)
tensor([.2.4320,.-0.4608,..0.7702])
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.4875, 0.9158, -0.5872],
[ 0.3938, -0.6929, 0.6932]])
>>> torch.t(x)
tensor([[ 0.4875, 0.3938],
[ 0.9158, -0.6929],
[-0.5872, 0.6932]])torch.take(input, index) → Tensor¶返回给定索引处带有input元素的新张量。 将输入张量视为视为一维张量。 结果采用与索引相同的形状。
Parameters
- input (Tensor) – the input tensor.
- 索引 (LongTensor )–张量索引
Example:
>>> src = torch.tensor([[4, 3, 5],
[6, 7, 8]])
>>> torch.take(src, torch.tensor([0, 2, 5]))
tensor([ 4, 5, 8])torch.transpose(input, dim0, dim1) → Tensor¶返回一个张量,该张量是input的转置版本。 给定的尺寸dim0和dim1被交换。
产生的out张量与input张量共享其基础存储,因此更改一个内容将更改另一个内容。
Parameters
- input (Tensor) – the input tensor.
- dim0 (python:int )–要转置的第一个维度
- dim1 (python:int )–要转置的第二维
Example:
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 1.0028, -0.9893, 0.5809],
[-0.1669, 0.7299, 0.4942]])
>>> torch.transpose(x, 0, 1)
tensor([[ 1.0028, -0.1669],
[-0.9893, 0.7299],
[ 0.5809, 0.4942]])torch.unbind(input, dim=0) → seq¶删除张量尺寸。
返回给定维度上所有切片的元组,已经没有它。
Parameters
- 输入 (tensor)–要解除绑定的张量
- 暗淡的 (python:int )–要移除的尺寸
Example:
>>> torch.unbind(torch.tensor([[1, 2, 3],
>>> [4, 5, 6],
>>> [7, 8, 9]]))
(tensor([1, 2, 3]), tensor([4, 5, 6]), tensor([7, 8, 9]))torch.unsqueeze(input, dim, out=None) → Tensor¶返回在指定位置插入的尺寸为 1 的新张量。
返回的张量与此张量共享相同的基础数据。
可以使用[-input.dim() - 1, input.dim() + 1)范围内的dim值。 负的dim对应于dim = dim + input.dim() + 1处应用的 unsqueeze()
。
Parameters
- input (Tensor) – the input tensor.
- 暗淡的 (python:int )–插入单例尺寸的索引
- out (Tensor, optional) – the output tensor.
Example:
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])torch.where()¶torch.where(condition, x, y) → Tensor返回从x或y中选择的元素的张量,具体取决于condition。
该操作定义为:
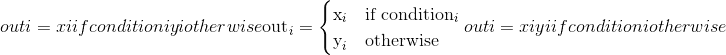
Note
张量condition,x和y必须是可广播的。
Parameters
- 条件 (BoolTensor)–当为 True(非零)时,产生 x,否则产生 y
- x (tensor)–在
condition为True的索引处选择的值 - y (tensor)–在
condition为False的索引处选择的值
Returns
形状张量等于condition,x,y的广播形状
Return type
Tensor
Example:
>>> x = torch.randn(3, 2)
>>> y = torch.ones(3, 2)
>>> x
tensor([[-0.4620, 0.3139],
[ 0.3898, -0.7197],
[ 0.0478, -0.1657]])
>>> torch.where(x > 0, x, y)
tensor([[ 1.0000, 0.3139],
[ 0.3898, 1.0000],
[ 0.0478, 1.0000]])torch.where(condition) → tuple of LongTensortorch.where(condition)与torch.nonzero(condition, as_tuple=True)相同。
Note
另请参见 torch.nonzero() 。
发电机
class torch._C.Generator(device='cpu') → Generator¶创建并返回一个生成器对象,该对象管理产生伪随机数的算法的状态。 在许多就地随机采样函数中用作关键字参数。
Parameters
设备(torch.device,可选)–生成器所需的设备。
Returns
一个 torch.Generator 对象。
Return type
生成器
Example:
>>> g_cpu = torch.Generator()
>>> g_cuda = torch.Generator(device='cuda')device¶Generator.device->设备
获取生成器的当前设备。
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu.device
device(type='cpu')get_state() → Tensor¶返回生成器状态为torch.ByteTensor。
Returns
一个torch.ByteTensor,其中包含将生成器还原到特定时间点的所有必要位。
Return type
Tensor
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu.get_state()initial_seed() → int¶返回用于生成随机数的初始种子。
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu.initial_seed()
2147483647manual_seed(seed) → Generator¶设置用于生成随机数的种子。 返回一个<cite>torch.生成器</cite>对象。 建议设置一个大种子,即一个具有 0 和 1 位平衡的数字。 避免在种子中包含许多 0 位。
Parameters
种子 (python:int )–所需的种子。
Returns
An torch.Generator object.
Return type
Generator
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu.manual_seed(2147483647)seed() → int¶从 std :: random_device 或当前时间获取不确定的随机数,并将其用作生成器的种子。
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu.seed()
1516516984916set_state(new_state) → void¶设置生成器状态。
Parameters
new_state (Torch.ByteTensor )–所需状态。
Example:
>>> g_cpu = torch.Generator()
>>> g_cpu_other = torch.Generator()
>>> g_cpu.set_state(g_cpu_other.get_state())随机抽样
torch.seed()¶将用于生成随机数的种子设置为不确定的随机数。 返回用于播种 RNG 的 64 位数字。
torch.manual_seed(seed)¶设置用于生成随机数的种子。 返回一个<cite>torch.生成器</cite>对象。
Parameters
seed (python:int) – The desired seed.
torch.initial_seed()¶返回长为 Python <cite>long</cite> 的用于生成随机数的初始种子。
torch.get_rng_state()¶以 <cite>torch.ByteTensor</cite> 的形式返回随机数生成器状态。
torch.set_rng_state(new_state)¶设置随机数生成器状态。
Parameters
new_state (torch.ByteTensor )–所需状态
torch.default_generator Returns the default CPU torch.Generator¶torch.bernoulli(input, *, generator=None, out=None) → Tensor¶从伯努利分布中提取二进制随机数(0 或 1)。
input张量应为包含用于绘制二进制随机数的概率的张量。 因此,input中的所有值都必须在以下范围内:
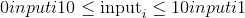 。
。
输出张量的
 元素将根据
元素将根据input中给出的
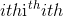 概率值绘制一个
概率值绘制一个
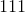 值。
值。
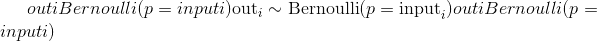
返回的out张量仅具有值 0 或 1,并且具有与input相同的形状。
out可以具有整数dtype,但是input必须具有浮点dtype。
Parameters
- 输入 (tensor)–伯努利分布的概率值的输入张量
- 生成器(
torch.Generator,可选)–用于采样的伪随机数生成器 - out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.empty(3, 3).uniform_(0, 1) # generate a uniform random matrix with range [0, 1]
>>> a
tensor([[ 0.1737, 0.0950, 0.3609],
[ 0.7148, 0.0289, 0.2676],
[ 0.9456, 0.8937, 0.7202]])
>>> torch.bernoulli(a)
tensor([[ 1., 0., 0.],
[ 0., 0., 0.],
[ 1., 1., 1.]])
>>> a = torch.ones(3, 3) # probability of drawing "1" is 1
>>> torch.bernoulli(a)
tensor([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> a = torch.zeros(3, 3) # probability of drawing "1" is 0
>>> torch.bernoulli(a)
tensor([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])torch.multinomial(input, num_samples, replacement=False, *, generator=None, out=None) → LongTensor¶返回一个张量,其中每行包含num_samples索引,这些索引是从位于张量input的相应行中的多项式概率分布中采样的。
Note
input的行不需要加总为 1(在这种情况下,我们将这些值用作权重),但必须为非负数,有限且总和为非零。
根据每个样本的采样时间,索引从左到右排序(第一个样本放在第一列中)。
如果input是向量,则out是大小num_samples的向量。
如果input是具有 <cite>m</cite> 行的矩阵,则out是形状
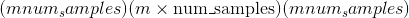 的矩阵。
的矩阵。
如果替换为True,则抽取样本进行替换。
如果没有,则它们将被替换而不会被绘制,这意味着当为一行绘制样本索引时,无法为该行再次绘制它。
Note
如果绘制时不进行替换,则num_samples必须小于input中非零元素的数目(如果是矩阵,则必须小于input每行中非零元素的最小数目)。
Parameters
- 输入 (tensor)–包含概率的输入张量
- num_samples (python:int )–要绘制的样本数
- 替换 (bool , 可选)–是否使用替换绘制
- generator (
torch.Generator, optional) – a pseudorandom number generator for sampling - out (Tensor, optional) – the output tensor.
Example:
>>> weights = torch.tensor([0, 10, 3, 0], dtype=torch.float) # create a tensor of weights
>>> torch.multinomial(weights, 2)
tensor([1, 2])
>>> torch.multinomial(weights, 4) # ERROR!
RuntimeError: invalid argument 2: invalid multinomial distribution (with replacement=False,
not enough non-negative category to sample) at ../aten/src/TH/generic/THTensorRandom.cpp:320
>>> torch.multinomial(weights, 4, replacement=True)
tensor([ 2, 1, 1, 1])torch.normal()¶torch.normal(mean, std, *, generator=None, out=None) → Tensor返回从均值和标准差给出的独立正态分布中得出的随机数张量。
mean 是一个张量,每个输出元素的正态分布均值
std 是一个张量,每个输出元素的正态分布的标准偏差
mean 和 std 的形状不需要匹配,但是每个张量中元素的总数必须相同。
Note
当形状不匹配时,将 mean 的形状用作返回的输出张量的形状
Parameters
- 均值 (tensor)–每个元素均值的张量
- std (tensor)–每个元素的标准偏差张量
- generator (
torch.Generator, optional) – a pseudorandom number generator for sampling - out (Tensor, optional) – the output tensor.
Example:
>>> torch.normal(mean=torch.arange(1., 11.), std=torch.arange(1, 0, -0.1))
tensor([ 1.0425, 3.5672, 2.7969, 4.2925, 4.7229, 6.2134,
8.0505, 8.1408, 9.0563, 10.0566])torch.normal(mean=0.0, std, out=None) → Tensor与上面的功能相似,但均值在所有绘制的元素之间共享。
Parameters
- 平均值 (python:float , 可选)–所有分布的平均值
- std (Tensor) – the tensor of per-element standard deviations
- out (Tensor, optional) – the output tensor.
Example:
>>> torch.normal(mean=0.5, std=torch.arange(1., 6.))
tensor([-1.2793, -1.0732, -2.0687, 5.1177, -1.2303])torch.normal(mean, std=1.0, out=None) → Tensor与上面的函数相似,但是标准偏差在所有绘制的元素之间共享。
Parameters
- mean (Tensor) – the tensor of per-element means
- std (python:float , 可选)–所有发行版的标准差
- out (tensor , 可选)–输出张量
Example:
>>> torch.normal(mean=torch.arange(1., 6.))
tensor([ 1.1552, 2.6148, 2.6535, 5.8318, 4.2361])torch.normal(mean, std, size, *, out=None) → Tensor与上述功能相似,但均值和标准差在所有绘制的元素之间共享。 所得张量的大小由size给出。
Parameters
- 平均值 (python:float )–所有分布的平均值
- std (python:float )–所有分布的标准偏差
- 大小 (python:int ... )–定义输出张量形状的整数序列。
- out (Tensor, optional) – the output tensor.
Example:
>>> torch.normal(2, 3, size=(1, 4))
tensor([[-1.3987, -1.9544, 3.6048, 0.7909]])torch.rand(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶从区间
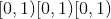 返回均匀分布的随机张量
返回均匀分布的随机张量
张量的形状由变量参数size定义。
Parameters
- size (python:int...) – a sequence of integers defining the shape of the output tensor. Can be a variable number of arguments or a collection like a list or tuple.
- out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.rand(4)
tensor([ 0.5204, 0.2503, 0.3525, 0.5673])
>>> torch.rand(2, 3)
tensor([[ 0.8237, 0.5781, 0.6879],
[ 0.3816, 0.7249, 0.0998]])torch.rand_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor¶返回与input大小相同的张量,该张量由间隔
 上均匀分布的随机数填充。
上均匀分布的随机数填充。 torch.rand_like(input)等效于torch.rand(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)。
Parameters
- input (Tensor) – the size of input will determine size of the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned Tensor. Default: ifNone, defaults to the dtype ofinput. - layout (
torch.layout, optional) – the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device(
torch.device, optional) – the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
torch.randint(low=0, high, size, *, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回一个由在low(包括)和high(不包括)之间均匀生成的随机整数填充的张量。
The shape of the tensor is defined by the variable argument size.
Parameters
- 低 (python:int , 可选)–从分布中得出的最低整数。 默认值:0
- 高 (python:int )–从分布中得出的最高整数之上一个。
- 大小(元组)–定义输出张量形状的元组。
- generator (
torch.Generator, optional) – a pseudorandom number generator for sampling - out (Tensor, optional) – the output tensor.
- dtype (torch.dtype, optional) – the desired data type of returned tensor. Default: if None, uses a global default (see torch.set_default_tensor_type()).
- layout (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.randint(3, 5, (3,))
tensor([4, 3, 4])
>>> torch.randint(10, (2, 2))
tensor([[0, 2],
[5, 5]])
>>> torch.randint(3, 10, (2, 2))
tensor([[4, 5],
[6, 7]])torch.randint_like(input, low=0, high, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶返回具有与张量input相同形状的张量,其中填充了在low(包括)和high(排除)之间均匀生成的随机整数。
Parameters
- input (Tensor) – the size of
inputwill determine size of the output tensor. - low (python:int__, optional) – Lowest integer to be drawn from the distribution. Default: 0.
- high (python:int) – One above the highest integer to be drawn from the distribution.
- dtype (
torch.dtype, optional) – the desired data type of returned Tensor. Default: ifNone, defaults to the dtype ofinput. - layout (
torch.layout, optional) – the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
torch.randn(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor¶从平均值为 <cite>0</cite> ,方差为 <cite>1</cite> 的正态分布中返回一个填充有随机数的张量(也称为标准正态分布)。
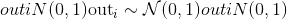
The shape of the tensor is defined by the variableargument size.
Parameters
- size (python:int...) – a sequence of integers defining the shape of the output tensor. Can be a variable number of arguments or a collection like a list or tuple.
- out (Tensor, optional) – the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned tensor. Default: ifNone, uses a global default (seetorch.set_default_tensor_type()). - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor.Default:
False.
Example:
>>> torch.randn(4)
tensor([-2.1436, 0.9966, 2.3426, -0.6366])
>>> torch.randn(2, 3)
tensor([[ 1.5954, 2.8929, -1.0923],
[ 1.1719, -0.4709, -0.1996]])torch.randn_like(input, dtype=None, layout=None, device=None, requires_grad=False) → Tensor¶返回一个与input相同大小的张量,该张量由均值 0 和方差 1 的正态分布的随机数填充。torch.randn_like(input)等效于torch.randn(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)。
Parameters
- input (Tensor) – the size of input will determine size of the output tensor.
- dtype (
torch.dtype, optional) – the desired data type of returned Tensor. Default: ifNone, defaults to the dtype ofinput. - layout (
torch.layout, optional) – the desired layout of returned tensor. Default: ifNone, defaults to the layout ofinput. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, defaults to the device ofinput. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
torch.randperm(n, out=None, dtype=torch.int64, layout=torch.strided, device=None, requires_grad=False) → LongTensor¶返回从0到n - 1的整数的随机排列。
Parameters
- n (python:int )–上限(不包括)
- out (Tenso, optional) – the output tensor.
- dtype(
torch.dtype,可选)–返回张量的所需数据类型。 默认值:torch.int64。 - layout (
torch.layout, optional) – the desired layout of returned Tensor. Default:torch.strided. - device (
torch.device, optional) – the desired device of returned tensor. Default: ifNone, uses the current device for the default tensor type (seetorch.set_default_tensor_type()).devicewill be the CPU for CPU tensor types and the current CUDA device for CUDA tensor types. - requires_grad (bool__, optional) – If autograd should record operations on the returned tensor. Default:
False.
Example:
>>> torch.randperm(4)
tensor([2, 1, 0, 3])就地随机抽样
在 Tensor 上还定义了一些就地随机采样函数。 单击以查看其文档:
torch.Tensor.bernoulli_()-torch.bernoulli()的就地版本torch.Tensor.cauchy_()-从柯西分布中得出的数字torch.Tensor.exponential_()-从指数分布中得出的数字torch.Tensor.geometric_()-从几何分布中绘制的元素torch.Tensor.log_normal_()-来自对数正态分布的样本torch.Tensor.normal_()-torch.normal()的就地版本torch.Tensor.random_()-从离散均匀分布中采样的数字torch.Tensor.uniform_()-从连续均匀分布中采样的数字
准随机抽样
class torch.quasirandom.SobolEngine(dimension, scramble=False, seed=None)¶torch.quasirandom.SobolEngine 是用于生成(加扰)Sobol 序列的引擎。 Sobol 序列是低差异准随机序列的一个示例。
用于 Sobol 序列的引擎的这种实现方式能够对最大维度为 1111 的序列进行采样。它使用方向编号生成这些序列,并且这些编号已从此处改编而来。
参考文献
- Art B. Owen。 争夺 Sobol 和 Niederreiter-Xing 点。 复杂性杂志,14(4):466-489,1998 年 12 月。
- I. M. Sobol。 立方体中点的分布和积分的准确评估。 嗯 Vychisl。 垫。 我在。 Phys。,7:784-802,1967。
Parameters
- 尺寸 (Int )–要绘制的序列的尺寸
- 扰乱 (bool , 可选)–将其设置为True将产生扰乱的 Sobol 序列。 加扰能够产生更好的 Sobol 序列。默认值:
False。 - 种子 (Int , 可选)–这是加扰的种子。 如果指定,则将随机数生成器的种子设置为此。 否则,它将使用随机种子。默认值:
None
例子:
>>> soboleng = torch.quasirandom.SobolEngine(dimension=5)
>>> soboleng.draw(3)
tensor([[0.5000, 0.5000, 0.5000, 0.5000, 0.5000],
[0.7500, 0.2500, 0.7500, 0.2500, 0.7500],
[0.2500, 0.7500, 0.2500, 0.7500, 0.2500]])draw(n=1, out=None, dtype=torch.float32)¶从 Sobol 序列中绘制n点序列的功能。 请注意,样本取决于先前的样本。 结果的大小为
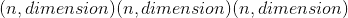 。
。
Parameters
- n (Int , 可选)–绘制点序列的长度。 默认值:1
- out (tensor , 可选)–输出张量
- dtype (
torch.dtype,可选)–返回的张量的所需数据类型。 默认值:torch.float32
fast_forward(n)¶通过n步骤快速前进SobolEngine状态的功能。 这等效于不使用样本绘制n样本。
Parameters
n (Int )–快进的步数。
reset()¶将SobolEngine重置为基本状态的功能。
序列化
torch.save(obj, f, pickle_module=<module 'pickle' from '/opt/conda/lib/python3.6/pickle.py'>, pickle_protocol=2, _use_new_zipfile_serialization=False)¶将对象保存到磁盘文件。
另请参见:推荐的模型保存方法
Parameters
- obj –保存的对象
- f –类似于文件的对象(必须实现写入和刷新)或包含文件名的字符串
- pickle_module –用于腌制元数据和对象的模块
- pickle_protocol –可以指定为覆盖默认协议
Warning
如果使用的是 Python 2,则 torch.save() 不支持StringIO.StringIO作为有效的类似文件的对象。 这是因为 write 方法应返回写入的字节数; StringIO.write()不这样做。
请改用io.BytesIO之类的东西。
例
>>> # Save to file
>>> x = torch.tensor([0, 1, 2, 3, 4])
>>> torch.save(x, 'tensor.pt')
>>> # Save to io.BytesIO buffer
>>> buffer = io.BytesIO()
>>> torch.save(x, buffer)torch.load(f, map_location=None, pickle_module=<module 'pickle' from '/opt/conda/lib/python3.6/pickle.py'>, **pickle_load_args)¶从文件加载用 torch.save() 保存的对象。
torch.load() 使用 Python 的解开工具,但会特别处理位于张量之下的存储。 它们首先在 CPU 上反序列化,然后移到保存它们的设备上。 如果失败(例如,因为运行时系统没有某些设备),则会引发异常。 但是,可以使用 map_location参数将存储动态重新映射到一组备用设备。
如果map_location是可调用的,则将为每个序列化存储调用一次,并带有两个参数:storage 和 location。 storage 参数将是驻留在 CPU 上的存储的初始反序列化。 每个序列化存储都有一个与之关联的位置标签,该标签标识了从中进行保存的设备,该标签是传递给map_location的第二个参数。 内置位置标签是用于 CPU 张量的'cpu'和用于 CUDA 张量的'cuda:device_id'(例如'cuda:2')。 map_location应该返回None或存储。
如果map_location返回存储,它将用作最终反序列化的对象,已经移至正确的设备。 否则, torch.load() 将退回到默认行为,就像未指定map_location一样。
如果map_location是 torch.device 对象或与设备标签冲突的字符串,则它指示应加载所有张量的位置。
否则,如果map_location是字典,它将用于将文件(键)中出现的位置标签重新映射到指定将存储位置(值)放置的位置标签。
用户扩展可以使用torch.serialization.register_package()注册自己的位置标签以及标记和反序列化方法。
Parameters
- f –类似于文件的对象(必须实现
read(),:methreadline,:methtell和:methseek)或包含文件名的字符串 - map_location –函数,
torch.device,字符串或指定如何重新映射存储位置的字典 - pickle_module –用于解开元数据和对象的模块(必须与用于序列化文件的
pickle_module匹配) - pickle_load_args –(仅适用于 Python 3)可选关键字参数传递给
pickle_module.load()和pickle_module.Unpickler(),例如errors=...。
Note
当您在包含 GPU 张量的文件上调用 torch.load() 时,这些张量将默认加载到 GPU。 您可以先调用torch.load(.., map_location='cpu'),然后再调用load_state_dict(),以避免在加载模型检查点时 GPU RAM 激增。
Note
默认情况下,我们将字节字符串解码为utf-8。 这是为了避免在 Python 3 中加载 Python 2 保存的文件时出现常见错误情况UnicodeDecodeError: 'ascii' codec can't decode byte 0x...。如果此默认设置不正确,则可以使用额外的encoding关键字参数来指定应如何加载这些对象,例如encoding='latin1'使用latin1编码将它们解码为字符串,encoding='bytes'将它们保留为字节数组,以后可以使用byte_array.decode(...)进行解码。
Example
>>> torch.load('tensors.pt')
## Load all tensors onto the CPU
>>> torch.load('tensors.pt', map_location=torch.device('cpu'))
## Load all tensors onto the CPU, using a function
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage)
## Load all tensors onto GPU 1
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage.cuda(1))
## Map tensors from GPU 1 to GPU 0
>>> torch.load('tensors.pt', map_location={'cuda:1':'cuda:0'})
## Load tensor from io.BytesIO object
>>> with open('tensor.pt', 'rb') as f:
buffer = io.BytesIO(f.read())
>>> torch.load(buffer)
## Load a module with 'ascii' encoding for unpickling
>>> torch.load('module.pt', encoding='ascii')平行性
torch.get_num_threads() → int¶返回用于并行化 CPU 操作的线程数
torch.set_num_threads(int)¶设置用于 CPU 上的内部运算并行的线程数。 警告:为确保使用正确的线程数,必须在运行 eager,JIT 或 autograd 代码之前调用 set_num_threads。
torch.get_num_interop_threads() → int¶返回用于 CPU 上的互操作并行的线程数(例如,在 JIT 解释器中)
torch.set_num_interop_threads(int)¶设置用于 CPU 上的互操作并行性(例如,在 JIT 解释器中)的线程数。 警告:只能在一次操作间并行工作开始之前(例如 JIT 执行)调用一次。
局部禁用梯度计算
上下文管理器torch.no_grad(),torch.enable_grad()和torch.set_grad_enabled()有助于局部禁用和启用梯度计算。 有关其用法的更多详细信息,请参见局部禁用梯度计算。 这些上下文管理器是线程本地的,因此如果您使用threading模块等将工作发送到另一个线程,它们将无法工作。
Examples:
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad():
... y = x * 2
>>> y.requires_grad
False
>>> is_train = False
>>> with torch.set_grad_enabled(is_train):
... y = x * 2
>>> y.requires_grad
False
>>> torch.set_grad_enabled(True) # this can also be used as a function
>>> y = x * 2
>>> y.requires_grad
True
>>> torch.set_grad_enabled(False)
>>> y = x * 2
>>> y.requires_grad
False数学运算
逐点操作
torch.abs(input, out=None) → Tensor¶计算给定input张量的按元素的绝对值。
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> torch.abs(torch.tensor([-1, -2, 3]))
tensor([ 1, 2, 3])torch.acos(input, out=None) → Tensor¶返回带有input元素的反余弦的新张量。
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 0.3348, -0.5889, 0.2005, -0.1584])
>>> torch.acos(a)
tensor([ 1.2294, 2.2004, 1.3690, 1.7298])torch.add()¶torch.add(input, other, out=None)将标量other添加到输入input的每个元素中,并返回一个新的结果张量。
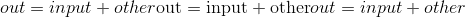
如果input的类型为 FloatTensor 或 DoubleTensor,则other必须为实数,否则应为整数。
Parameters
- input (Tensor) – the input tensor.
- 值(编号)–要添加到
input每个元素的编号
Keyword Argumentsout (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 0.0202, 1.0985, 1.3506, -0.6056])
>>> torch.add(a, 20)
tensor([ 20.0202, 21.0985, 21.3506, 19.3944])torch.add(input, alpha=1, other, out=None)张量other的每个元素乘以标量alpha,然后加到张量input的每个元素上。 返回结果张量。
input和other的状必须是可广播的。

如果other的类型为 FloatTensor 或 DoubleTensor,则alpha必须为实数,否则应为整数。
Parameters
- 输入 (tensor)–第一个输入张量
- alpha (数字)–
other的标量乘法器 - 其他 (tensor)–第二个输入张量
Keyword Argumentsout (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([-0.9732, -0.3497, 0.6245, 0.4022])
>>> b = torch.randn(4, 1)
>>> b
tensor([[ 0.3743],
[-1.7724],
[-0.5811],
[-0.8017]])
>>> torch.add(a, 10, b)
tensor([[ 2.7695, 3.3930, 4.3672, 4.1450],
[-18.6971, -18.0736, -17.0994, -17.3216],
[ -6.7845, -6.1610, -5.1868, -5.4090],
[ -8.9902, -8.3667, -7.3925, -7.6147]])torch.addcdiv(input, value=1, tensor1, tensor2, out=None) → Tensor¶执行tensor1除以tensor2的元素,将结果乘以标量value并将其加到input上。
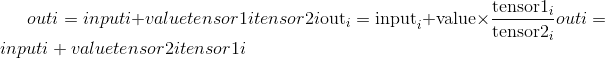
input,tensor1和tensor2的形状必须是可广播。
对于类型为 <cite>FloatTensor</cite> 或 <cite>DoubleTensor</cite> 的输入,value必须为实数,否则为整数。
Parameters
- 输入 (tensor)–要添加的张量
- 值(编号 , 可选)–
的乘数
- 张量 1 (tensor)–分子张量
- 张量 2 (tensor)–分母张量
- out (Tensor, optional) – the output tensor.
Example:
>>> t = torch.randn(1, 3)
>>> t1 = torch.randn(3, 1)
>>> t2 = torch.randn(1, 3)
>>> torch.addcdiv(t, 0.1, t1, t2)
tensor([[-0.2312, -3.6496, 0.1312],
[-1.0428, 3.4292, -0.1030],
[-0.5369, -0.9829, 0.0430]])torch.addcmul(input, value=1, tensor1, tensor2, out=None) → Tensor¶对tensor1与tensor2进行元素逐项乘法,将结果与标量value相乘,然后将其与input相加。
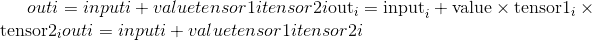
tensor ,tensor1和tensor2的形状必须是可广播的。
For inputs of type <cite>FloatTensor</cite> or <cite>DoubleTensor</cite>, value must be a real number, otherwise an integer.
Parameters
- input (Tensor) – the tensor to be added
- 值(编号 , 可选)–
的乘数
- 张量 1 (tensor)–要相乘的张量
- 张量 2 (tensor)–要相乘的张量
- out (Tensor, optional) – the output tensor.
Example:
>>> t = torch.randn(1, 3)
>>> t1 = torch.randn(3, 1)
>>> t2 = torch.randn(1, 3)
>>> torch.addcmul(t, 0.1, t1, t2)
tensor([[-0.8635, -0.6391, 1.6174],
[-0.7617, -0.5879, 1.7388],
[-0.8353, -0.6249, 1.6511]])torch.angle(input, out=None) → Tensor¶计算给定input张量的元素方向角(以弧度为单位)。
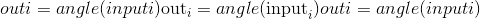
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> torch.angle(torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j]))*180/3.14159
tensor([ 135., 135, -45])torch.asin(input, out=None) → Tensor¶返回带有input元素的反正弦值的新张量。
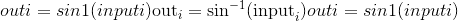
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([-0.5962, 1.4985, -0.4396, 1.4525])
>>> torch.asin(a)
tensor([-0.6387, nan, -0.4552, nan])torch.atan(input, out=None) → Tensor¶返回带有input元素的反正切的新张量。
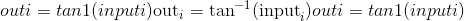
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 0.2341, 0.2539, -0.6256, -0.6448])
>>> torch.atan(a)
tensor([ 0.2299, 0.2487, -0.5591, -0.5727])torch.atan2(input, other, out=None) → Tensor¶考虑象限的
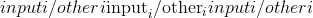 元素逐级反正切。 返回一个新的张量,其矢量
元素逐级反正切。 返回一个新的张量,其矢量
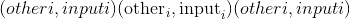 与矢量
与矢量
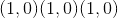 之间的弧度为符号角。 (请注意,第二个参数
之间的弧度为符号角。 (请注意,第二个参数
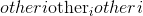 是 x 坐标,而第一个参数
是 x 坐标,而第一个参数
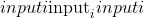 是 y 坐标。)
是 y 坐标。)
iinput和other的形状必须是可广播的。
Parameters
- input (Tenso) – the first input tensor
- other (Tensor) – the second input tensor
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 0.9041, 0.0196, -0.3108, -2.4423])
>>> torch.atan2(a, torch.randn(4))
tensor([ 0.9833, 0.0811, -1.9743, -1.4151])torch.bitwise_not(input, out=None) → Tensor¶计算给定输入张量的按位非。 输入张量必须是整数或布尔类型。 对于布尔张量,它计算逻辑非。
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example
>>> torch.bitwise_not(torch.tensor([-1, -2, 3], dtype=torch.int8))
tensor([ 0, 1, -4], dtype=torch.int8)torch.bitwise_xor(input, other, out=None) → Tensor¶计算input和other的按位 XOR。 输入张量必须是整数或布尔类型。 对于布尔张量,它计算逻辑 XOR。
Parameters
- 输入 –第一个输入张量
- 其他 –第二个输入张量
- out (Tensor, optional) – the output tensor.
Example
>>> torch.bitwise_xor(torch.tensor([-1, -2, 3], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([-2, -2, 0], dtype=torch.int8)
>>> torch.bitwise_xor(torch.tensor([True, True, False]), torch.tensor([False, True, False]))
tensor([ True, False, False])torch.ceil(input, out=None) → Tensor¶返回带有input元素的 ceil 的新张量,该元素大于或等于每个元素的最小整数。

Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([-0.6341, -1.4208, -1.0900, 0.5826])
>>> torch.ceil(a)
tensor([-0., -1., -1., 1.])torch.clamp(input, min, max, out=None) → Tensor¶将input中的所有元素限制在 <cite>[</cite> min , max <cite>]</cite> 范围内,并返回结果张量:
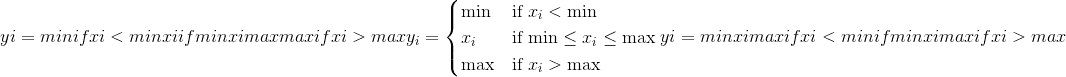
如果input的类型为 <cite>FloatTensor</cite> 或 <cite>DoubleTensor</cite> ,则参数 min 和 max 必须为实数,否则为实数 应该是整数。
Parameters
- input (Tensor) – the input tensor.
- min (编号)–要钳制的范围的下限
- 最大(编号)–要钳位的范围的上限
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([-1.7120, 0.1734, -0.0478, -0.0922])
>>> torch.clamp(a, min=-0.5, max=0.5)
tensor([-0.5000, 0.1734, -0.0478, -0.0922])torch.clamp(input, *, min, out=None) → Tensor将input中的所有元素限制为大于或等于 min 。
如果input的类型为 <cite>FloatTensor</cite> 或 <cite>DoubleTensor</cite> ,则value应为实数,否则应为整数。
Parameters
- input (Tensor) – the input tensor.
- 值(编号)–输出中每个元素的最小值
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([-0.0299, -2.3184, 2.1593, -0.8883])
>>> torch.clamp(a, min=0.5)
tensor([ 0.5000, 0.5000, 2.1593, 0.5000])torch.clamp(input, *, max, out=None) → Tensor将input中的所有元素限制为小于或等于 <max。
If input is of type <cite>FloatTensor</cite> or <cite>DoubleTensor</cite>, value should be a real number, otherwise it should be an integer.
Parameters
- input (Tensor) – the input tensor.
- 值(编号)–输出中每个元素的最大值
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 0.7753, -0.4702, -0.4599, 1.1899])
>>> torch.clamp(a, max=0.5)
tensor([ 0.5000, -0.4702, -0.4599, 0.5000])torch.conj(input, out=None) → Tensor¶计算给定input张量的逐元素共轭。
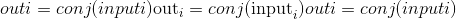
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> torch.conj(torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j]))
tensor([-1 - 1j, -2 - 2j, 3 + 3j])torch.cos(input, out=None) → Tensor¶返回带有input元素的余弦的新张量。
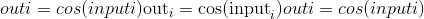
Parameters
- input (Tensor) – the input tensor.
- out (Tensor, optional) – the output tensor.
Example:
>>> a = torch.randn(4)
>>> a
tensor([ 1.4309, 1.2706, -0.8562, 0.9796])
>>> torch.cos(a)
tensor([ 0.1395, 0.2957, 0.6553, 0.5574])torch.cosh(input, out=None) → Tensor¶返回具有input元素的双曲余弦的新张量。
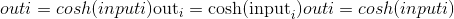
Parameters
- input (Tensor) – the input tensor.
- out (