
文心千帆创建大模型调优任务
2023-07-19 16:07 更新
大模型调优实际上是Fine-Tuning的训练模式,开发者可以选择适合自己任务场景的训练模式并加以调参训练,从而实现理想的模型效果。
登录到文心千帆大模型操作台,在左侧功能列选择大模型调优,进入大模型调优主任务界面。
创建任务
您需要在大模型调优任务界面,选择“创建调优任务”按钮。
填写好任务名称后,在范围内选择所属行业和应用场景,再进行500字内的业务描述即可。
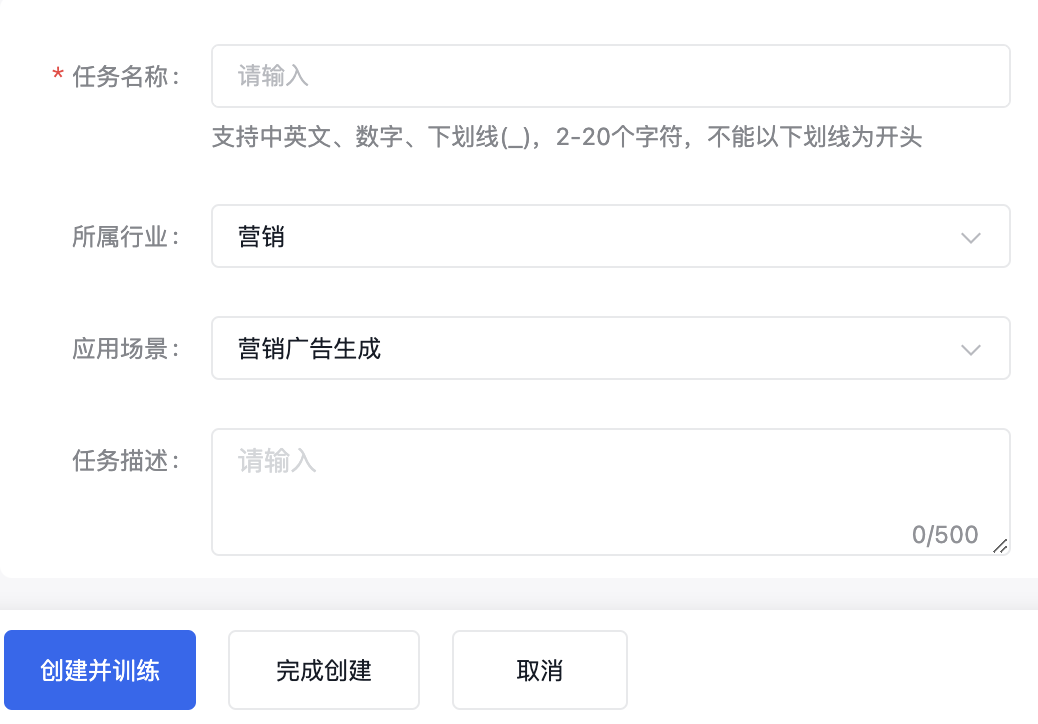
创建并训练直接开启训练模型的运行配置界面;“完成创建”仅创建任务不创建训练模型的运行。
新建运行
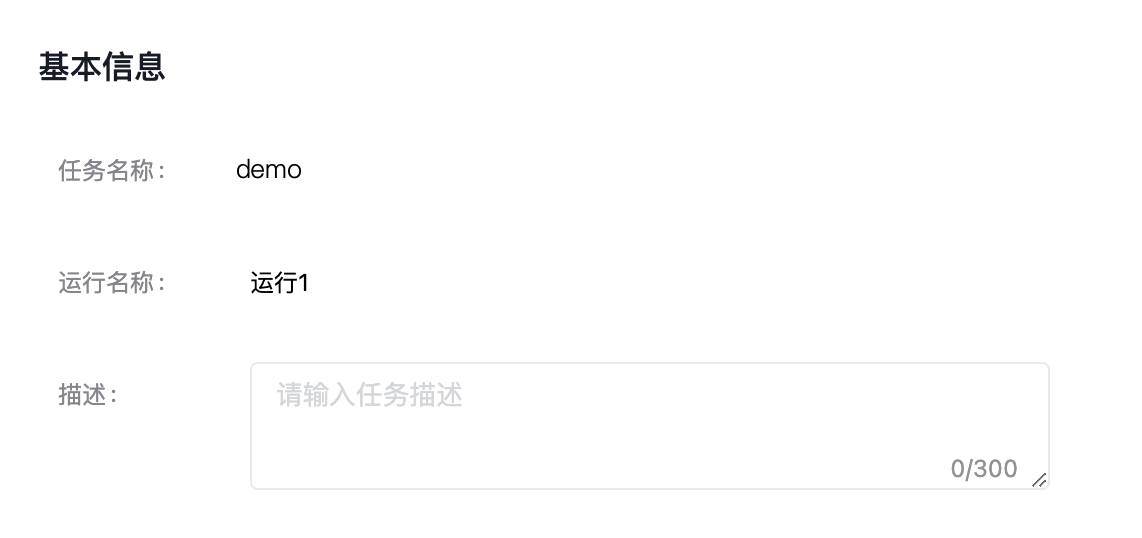
您可以在创建任务时选择“创建并训练”,或者在大模型调优任务列表中,选择指定任务的“新建运行”按钮。进入模型训练的任务运行配置页,填写基本信息。
训练配置
训练配置大模型参数,调整好基本配置。
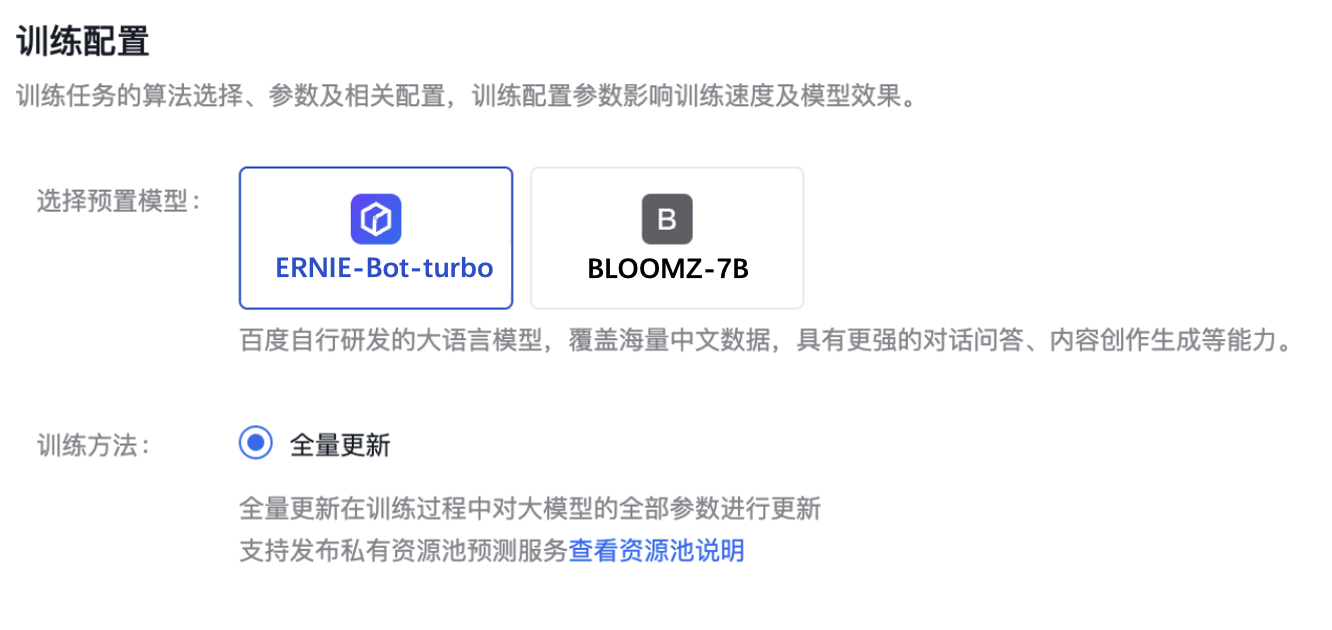
·ERNIE-Bot-turbo
百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
·BLOOMZ-7B
知名的大语言模型,由HuggingFace研发并开源,能够以46种语言和13种编程语言输出文本。
| 训练方法 | 简单描述 |
|---|---|
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新 |
| Prompt Tuning | 在固定预训练大模型本身的参数的基础上,增加prompt embedding参数,并且训练过程中只更新prompt参数。 |
| LoRA | 在固定预训练大模型本身的参数的基础上,在保留自注意力模块中原始权重矩阵的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分的参数。 |
- 参数配置
| 超参数 | 简单描述 |
|---|---|
| 迭代轮次 | 迭代轮次(epoch),控制训练过程中的迭代轮数。 |
| 批处理大小 | 批处理大小(Batchsize)表示在每次训练迭代中使用的样本数。较大的批处理大小可以加速训练,但可能会导致内存问题。 |
| 学习率 | 学习率(learning_rate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 梯度累积次数 | 梯度累积次数(gradient_accumulation_steps),累积几次原本的loss就要除以几,这是为了对多个批次的数据的梯度做累积,从而达到节省显存的目的。 |
数据配置
训练任务的选择数据及相关配置,大模型调优任务需要匹配多轮对话-非排序类的数据集。
建议数据集总条数在1000条以上,训练模型更加精准。
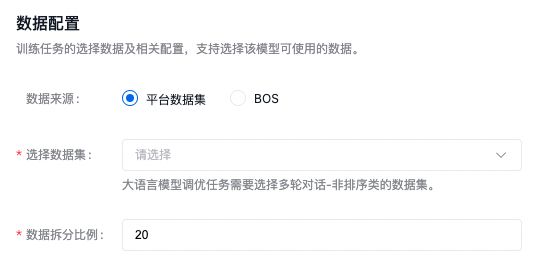
数据集来源可以为千帆平台已发布的数据集版本,也可以为已有数据集的BOS地址,详细内容可查看数据集部分内容。当预置模型选择BLOOMZ-7B时,需要设置数据拆分比例。比如设置20,则表示选定数据集版本总数的80%作为训练集,20%作为验证集。
需注意:当选择BOS目录导入数据集时,数据放在jsonl文件夹下。您需要选择jsonl的父目录:
- 奖励模型支持单轮对话、多轮对话有排序数据。
- RLHF训练支持仅prompt数据。
- SFT支持单轮对话,多轮对话需要有标注数据。
- BOS目录导入数据要严格遵守其格式要求,如不符合此格式要求,训练作业无法成功开启。详情参考BOS目录导入无标注信息格式和BOS目录导入有标注信息格式。
百度BOS服务开通申请。
以上所有操作完成后,点击“开始训练”,则发起模型训练的任务。