苹果发布MM1:30B规模多模态LLM
苹果加入战场,发布了自己的大语言模型 MM1,这是一个最高有 30B 规模的多模态 LLM。论文关键信息如下:
- 图像分辨率、图像编码器的预训练数据和模型大小对性能有显著影响。
- 视觉-语言连接器的设计相比之下影响较小。
- 预训练数据的混合比例对于少样本和零样本(zero-shot)性能至关重要。
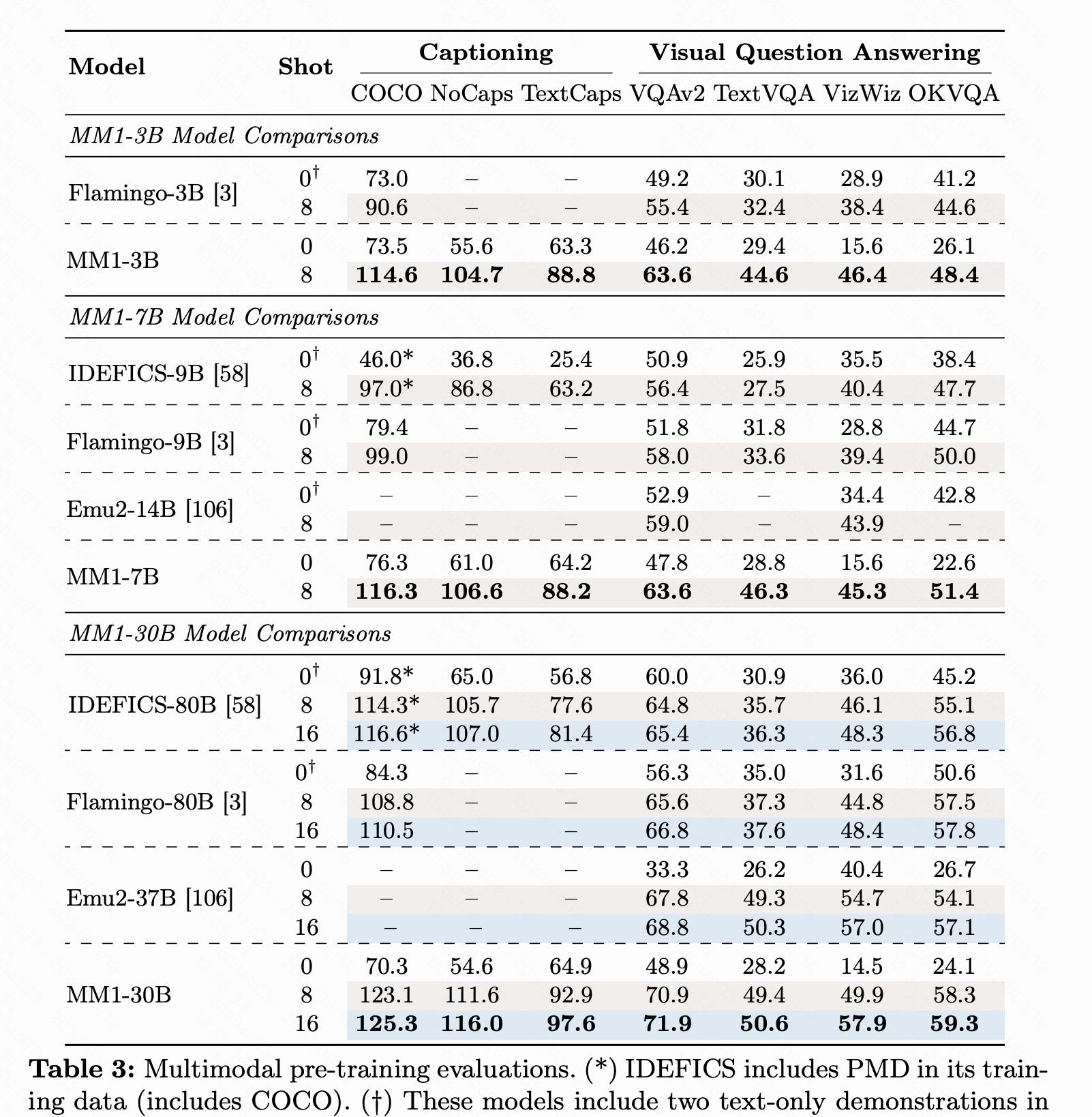
- 通过预训练和SFT,MM1模型在多个基准测试中取得了SOTA性能。
- MM1模型展现了一些吸引人的特性,如上下文内预测、多图像推理和少样本学习能力。
模型实现方案包括:
- 架构组件和数据选择的消融实验。
- 图像编码器:研究了不同预训练图像编码器的影响,以及图像分辨率和图像标记数量的重要性。
- 视觉-语言连接器:探讨了不同类型的视觉-语言连接器(如平均池化、注意力池化和C-Abstractor)对模型性能的影响。
- 预训练数据:使用了图像标题、交错的图像-文本和纯文本数据,研究了这些数据类型及其混合比例对模型性能的影响。
模型构建和预训练过程涉及:
- 扩大模型规模,包括密集模型和混合专家(mixture-of-experts,简称MoE)变体,构建了一系列性能优越的多模态模型。
- 在预训练过程中,使用大规模的多模态数据集,并通过特定的数据混合比例来训练模型。
性能评估和结果包括:
- 评估了预训练模型在多个基准测试中的性能,包括图像标题和视觉问答(VQA)任务。
- 通过监督式微调(Supervised Fine-Tuning,简称SFT),在一系列多模态基准测试中取得了有竞争力的性能。
论文地址:点击查看论文
@苹果 @MM1 @多模态LLM