用开源项目搭建的面试工具,项目为 https://github.com/SevaSk/ecoute
它可以实时帮你把对话理解,回答面试官的问题,你只需要照着读就可以了。
如果可以提前丢一些你的简历,让gpt学习下,效果可能更好。
Ecoute是什么?
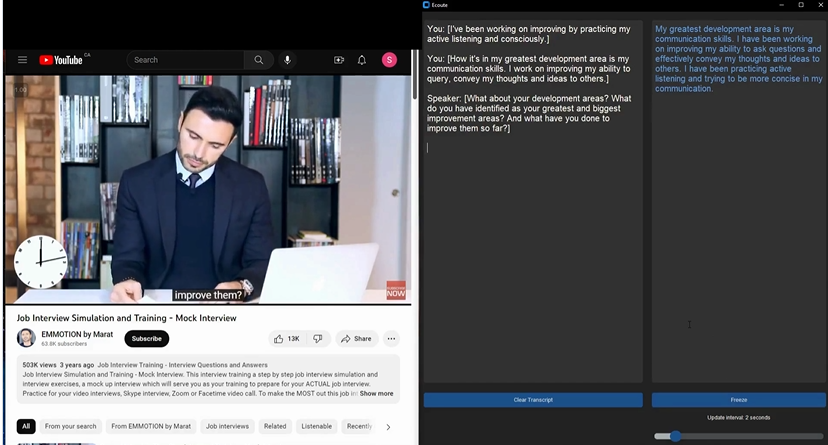
Ecoute 是一款开源的实时转录工具,可在文本框中提供用户麦克风输入 (You) 和用户扬声器输出 (Speaker) 的实时转录。它还使用 OpenAI 的 GPT-3.5 生成建议响应,供用户根据对话的实时转录说出建议。
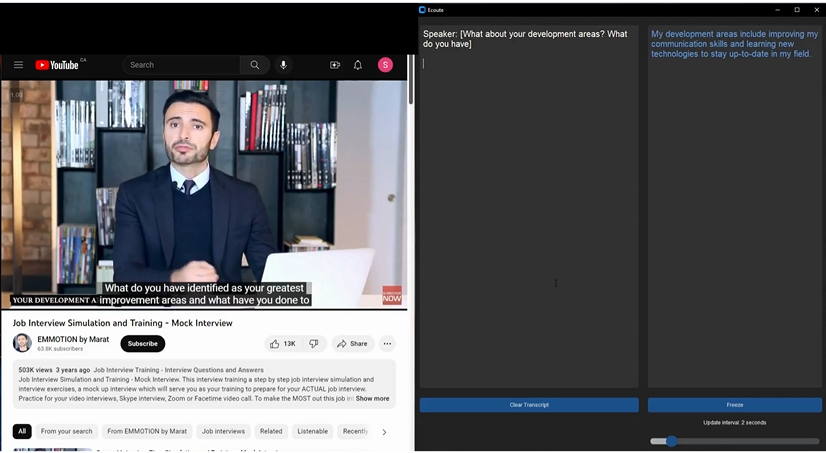
Ecoute 旨在通过提供实时转录并生成上下文相关的响应来帮助用户进行对话。通过利用 OpenAI 的 GPT-3.5 的强大功能,Ecoute 旨在让沟通变得更加高效和愉快。
如何安装和使用?
请按照以下步骤在本地计算机上设置并运行 Ecoute。
📋条件
- Python >=3.8.0
- 一个可以访问OpenAI API的OpenAI API密钥(设置付费帐户OpenAI帐户)
- Windows 操作系统(未在其他操作系统上测试)
- FFmpeg
如果您的系统中未安装 FFmpeg,您可以按照以下步骤进行安装。
首先,您需要安装 Chocolatey,一个 Windows 包管理器。
以管理员身份打开 PowerShell 并运行以下命令:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
安装 Chocolatey 后,您可以通过在 PowerShell 中运行以下命令来安装 FFmpeg:
choco install ffmpeg
请确保您以管理员权限在 PowerShell 窗口中运行这些命令。
如果您在安装过程中遇到任何问题,可以访问Chocolatey和FFmpeg官方网站进行排查。
🔧安装
克隆存储库:
git clone https://github.com/SevaSk/ecoute导航到ecoute文件夹:
cd ecoute安装所需的软件包:
pip install -r requirements.txtkeys.py在 ecoute 目录中创建一个文件并添加您的 OpenAI API 密钥:
选项 1:您可以在命令提示符下使用命令。运行以下命令,确保将“API KEY”替换为您的实际 OpenAI API 密钥:
python -c "with open('keys.py', 'w', encoding='utf-8') as f: f.write('OPENAI_API_KEY=\"API KEY\"')" 选项 2:您可以手动创建keys.py 文件。打开您选择的文本编辑器并输入以下内容:
OPENAI_API_KEY="API KEY"将“API KEY”替换为您的实际 OpenAI API 密钥。将此文件保存为 ecoute 目录中的keys.py。
🎬 运行Ecoute
运行主脚本:
python main.py
要获得更好、更快、也适用于大多数语言的版本,请使用:
python main.py --api
启动后,Ecoute 将开始实时转录您的麦克风输入和扬声器输出,并根据对话生成建议的响应。请注意,在转录变为实时之前,系统可能需要几秒钟的时间来预热。
--api 标志将使用 Whisper api 进行转录。这显着提高了转录速度和准确性,并且它适用于大多数语言(而不仅仅是没有标志的英语)。预计它将成为未来版本中的默认选项。但是,请记住,使用 Whisper API 会比使用本地模型消耗更多的 OpenAI 积分。这种增加的成本归因于 Whisper API 提供的高级特性和功能。尽管会产生额外费用,但速度和转录准确性的大幅提高可能使其成为您用例的值得投资。
⚠️局限性
虽然 Ecoute 提供实时转录和响应建议,但您应该注意其功能的一些已知限制:
默认麦克风和扬声器: Ecoute 当前配置为仅监听系统中设置的默认麦克风和扬声器。它不会检测来自其他设备或系统的声音。如果您想使用不同的麦克风或扬声器,则需要在系统设置中将其设置为默认设备。
Whisper 模型:如果不使用 --api 标志,我们将使用 Whisper ASR 模型的“微型”版本,因为它的资源消耗低且响应时间快。然而,在转录某些类型的语音(包括口音或不常见的单词)时,该模型可能不如较大的模型准确。
语言:如果您不使用 --api 标志,Ecoute 中使用的 Whisper 模型将设置为英语。因此,它可能无法准确转录非英语语言或方言。我们正在积极努力为该程序的未来版本添加多语言支持。